The big news is that I've ported Anukari to NVIDIA's CUDA GPU framework, and all of the goldens tests are passing -- it appears to work perfectly at this point. And it's very fast. Anukari was already pretty fast on NVIDIA hardware, and for simple presets the difference isn't huge (maybe 5-10%), but for complex presets the difference is transformative.
This improvement mostly comes from the fact that NVIDIA (like Apple) chose to artificially limit the amount of GPU block/threadgroup parallelism on OpenCL to force developers to migrate to their bespoke APIs. Both NVIDIA and Apple allow a maximum parallelism of 256 threads within a block/threadgroup, whereas both actually support 1024 if you use their APIs.
The reason this helps Anukari is that for large presets that contain more than 256 objects, on OpenCL it would have to process more than one object per thread, per audio sample. This roughly doubled the processing latency once that 257th object was added. And furthermore it went up again at 513, where each thread had to loop over three objects, and so on.
Now much larger presets are possible with very good performance. On Windows, at least, I am finally pretty dang happy with Anukari's performance. MacOS is getting very close, and with a buffer size of 512 it's solid. But with smaller buffer sizes it's still not quite perfect.
Fortunately, I have two more big optimizations up my sleeve. The biggest one is that now that I've ported to both Metal and CUDA, with the larger thread counts, I will be able to do further optimization with regards to warp divergence. I wrote about this a bit last year when I originally implemented warp alignment, which at that time was the biggest optimization to date.
But now with greater parallelism, I have access to way more warps. And in the meantime, I have added quite a few new object types with highly-divergent code paths. So it's time to improve the warp alignment so that the objects running within each warp have much better branch homogeneity. I am expecting some very substantial performance improvements for highly-complex instruments that make use of several kinds of modulators and exciters.
The old algorithm was a kind of greedy brute-force search for the best warp layout. But that was with 4 entity types, and now there are 11. Brute-force is no longer feasible within the necessary latency constraints. So I've devised a heuristic search algorithm. Basically it starts by creating what it thinks would be the optimal layout, and if that layout fits the hardware, it uses it. Otherwise, it will iterate over a priority-ordered list of possible compressions of the layout, taking the one that has the least performance drag. It will do this in a loop until finding a layout that fits the hardware. This algorithm will be guaranteed to find a solution because the last possible compression it will try is "just delete some padding between warps," which in the worst-case will just result in a layout with no warp alignment whatsoever.
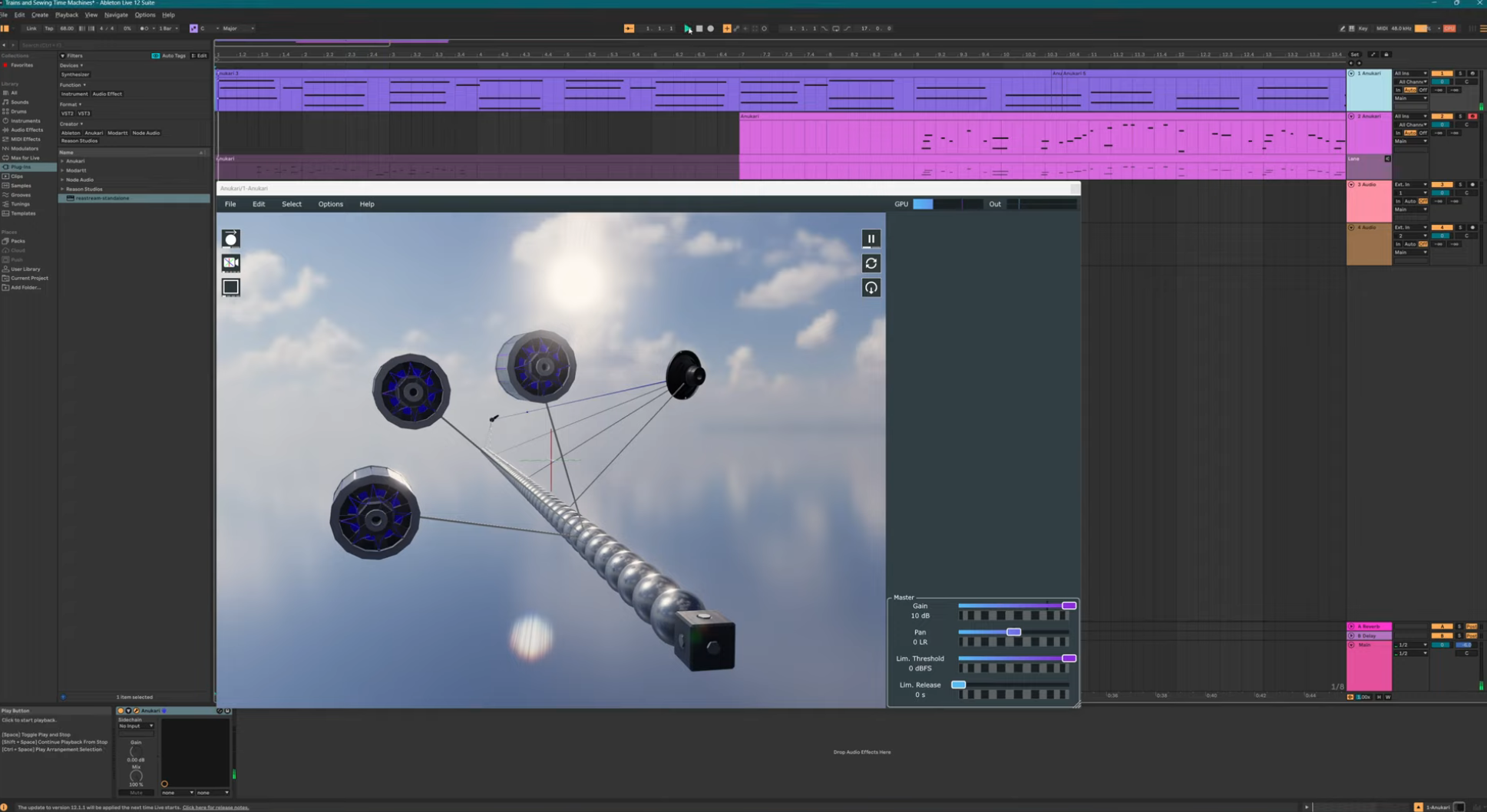
Anyway, here's a demo using the latest CUDA version of the simulation, which allows two voice-instanced instruments to run in parallel (with OBS capturing the screen, which is very bad for GPU performance):






.jpg)