Captain's Log: Stardate 77418
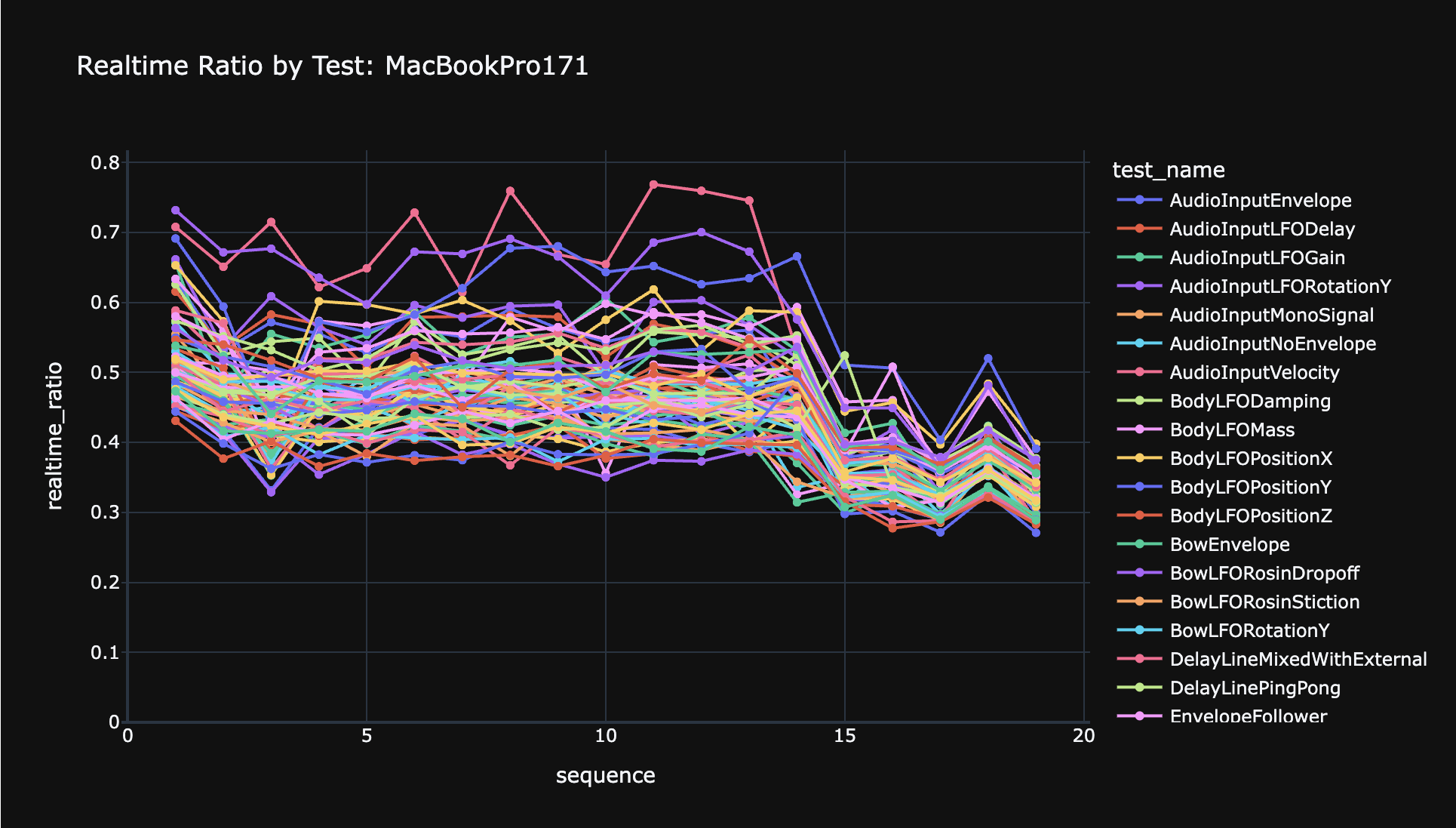
Well, that was an adventure. After bisecting commits to find the performance regression I mentioned yesterday, it turned out to be that I had changed the order in which the various entity types were serialized into GPU memory. Changing the order back fixed the performance. This was fairly interesting, as it's not entirely obvious why this memory order should matter.
It turns out that the reason this matters is that the way Anukari's GPU code works, there's essentially a big switch statement for entity types like BODY, SENSOR, EXCITER, etc. And each branch of the switch has significantly different code. So, if two entity types run on the same NVIDIA warp, performance drops because within a warp the execution is fairly SIMD-like. However, if two entity types run on different warps with no overlap, they both run really fast because of the homogeneity of the branch path within each warp.
I had always meant to do some optimization work to better pad/align things to try to homogenize that types of entities running on each warp. So, today, I did that. Anukari now tries really hard to only run a single entity type within a single warp, and only results to mixing entity types on a warp if there are too many entities to waste threads on padding entities (which are, essentially, NOOP entities).
This works now, though God it needs tests, because it is ridiculously complex. The benefits are pretty huge -- anywhere from a 25% to 50% reduction in kernel execution latency, depending on the preset and how badly misaligned it was by nature of the number of entities it included. The best part, though, is just that the performance is much more stable. E.g. adding a single mass is much less likely to cause a big performance hit due to changing the alignment.





.jpg)