Captain's Log: Stardate 78324
I've been really digging into MacOS optimizations over the last few days. Being ALU-bound is quite a pain in the butt, because unlike being memory-bound, there are a lot fewer big changes I can make to speed things up. Mostly I've been working on instruction-level optimizations, none of which have had a big impact. I've gotten to where I don't see anything else that is really worth optimizing at this level. I've confirmed that by simply commenting out pieces of code and measuring the speedup from not running it, which gives me an upper bound on how much optimizing it could help. Reducing computation at this point is not going to be done at the instruction level.
I have a couple ideas for larger structural/algorithmic changes, but before I move on to this, I want to eliminate a few other issues that I've noticed with MacOS.
The biggest pain I've run into is the fact that MacOS gives the user very little (almost no) control over the power/performance state of the machine. I guess this is user-friendly, as Apple magically figures out how best to clock the CPU and GPU up and down to save power, but it turns out that Apple is doing this really badly for Anukari's use case.
From what I can tell, Apple's GPU clock throttling is based on something akin to a load average. This is a concept I originally ran into from Unix, where the load average is, roughly speaking, the average number of threads that are awaiting execution at any moment. If this number is higher than the number of CPU cores, it means that there's a backlog: there are regularly threads that want to run, but can't.
On the Apple GPU, it seems that the OS won't clock it up until there's a command queue with a high load average. Which makes sense for throughput-sensitive use cases, but doesn't work at all for a latency-sensitive use case. For example, for graphics, as long as the command queue isn't backing up (load average > 1), there's no need to up-clock the GPU: it is keeping up. But for Anukari, this heuristic doesn't work, because if it ever hits a load average even close to 1, that means that there's no wallclock time left over for e.g. the DAW to process the audio block, etc. It's already too late, and audio glitches are regularly occurring even at something like 0.8.
This is a serious problem. I asked on the Apple Developer Forums (optimistic, I know), and though I did get a thoughtful response, it wasn't from an Apple developer, and it didn't help anyway. I ran numerous experiments with queuing more simulation kernels in advance, but ultimately none of these ideas helped, because ultimately I can't really generate audio in advance because I need up-to-date MIDI input, etc.
Ultimately, the solution that I am going with is probably the stupidest code that I will have ever shipped to production in my career: Anukari is dedicating one GPU threadgroup warp to useless computation, simply to keep it fully saturated to communicate to the OS that the GPU needs to be up-clocked. So in this case, waste makes haste.
But while this is incredibly stupid, it is also incredibly effective. I got it working with the minimal amount of power usage by dedicating the smallest amount of compute possible to spinning (not even a whole threadgroup, just one warp). And it immediately gets the OS to clock up the GPU, which decreases the audio computation latency by about 40%.
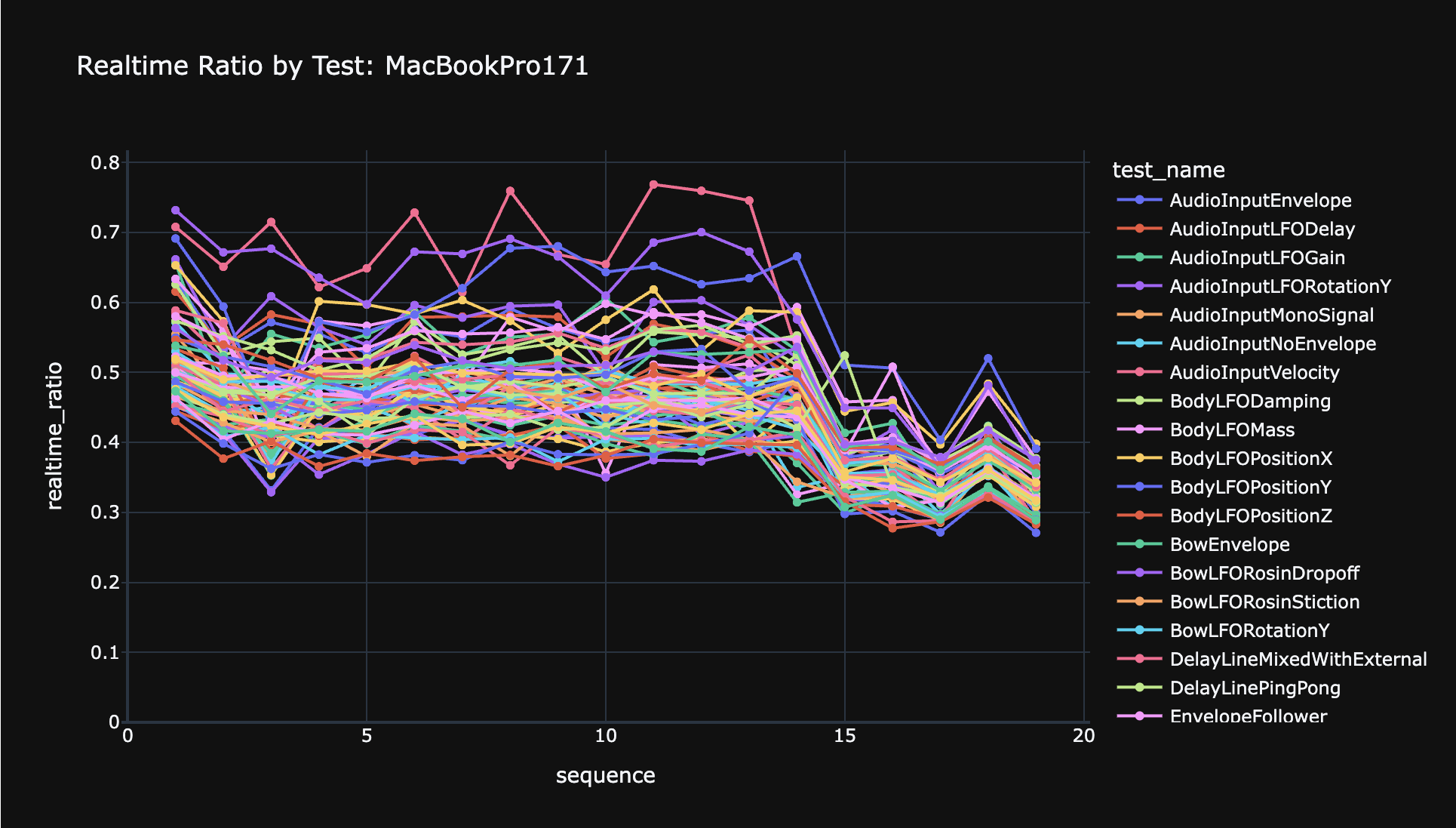
My new golden test latency stats framework doesn't show as much of a gain as I see when using the plugin, because it was already running the GPU with smaller gaps, as it doesn't need to wait for real time to render the audio. But even in the tests, the performance improvement is dramatic. In this graph you can see the overall real time ratio for the tests. The huge drop at iteration 15 is where I implemented the GPU spin:

Here is a graph with all the tests broken out individually:
At this point, on my Macbook M1, the standalone app performance is very usable, even for quite complicated presets like the slinky-resocube.
But... of course nothing is ever simple, and somehow while these fantastic performance gains are very observable when running as a VST3 plugin in Ableton, they are not nearly as visible when running as an AU plugin in GarageBand. I don't know what is up here, but it needs to be the next performance issue that I address, because if I can get past this, I might have performance at a "good enough" level on MacOS to start spending my time elsewhere for a while.


Captain's Log: Stardate 78674.7
Evan Mezeske
Mar 2025
Captain's Log: Stardate 78275.5
Evan Mezeske
Oct 2024

Captain's Log: Stardate 78006.4
Evan Mezeske
Jul 2024



.jpg)