Stories from my Meebo years, including the HR outage that made Trampoline Enthusiast my official job title and the great finger rocket wars.
Evan Mezeske
Jun 2026
Why I replaced Google Filament with 40K lines of custom PBR engine code, written with Claude in weeks, that survives VK_DEVICE_LOST without crashing.
Release 0.9.30 adds post-processing shaders and 1-click screen recording. The recorder alone is 6,500 lines of platform-specific C++, built with Claude.
Mar 2026
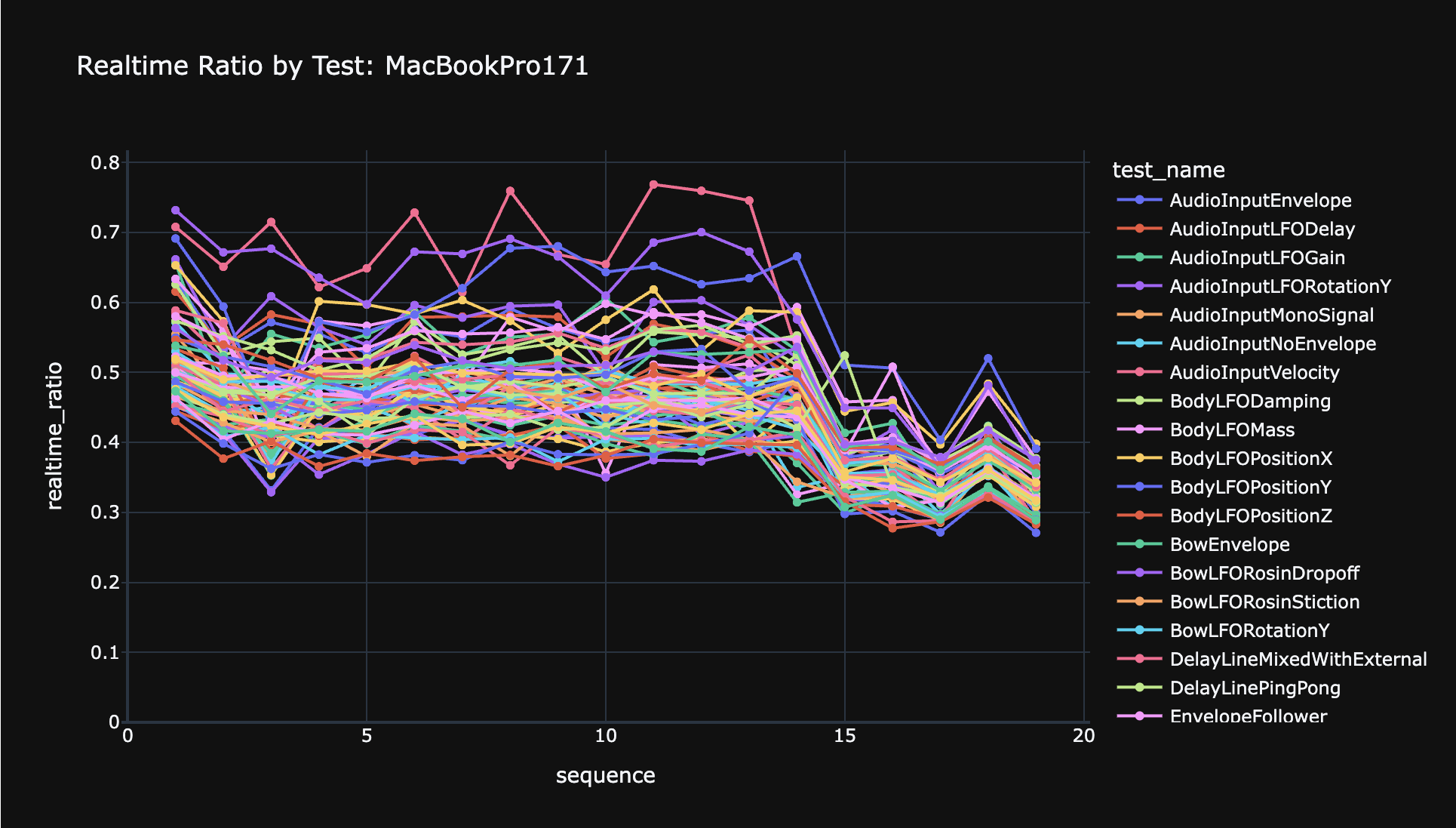
Looking back at the GPU years, where my 50,000-object goal led me astray, and why one SIMD backend beats maintaining CUDA, Metal, and OpenCL.
Nov 2025
Part 2 of the CPU rewrite, from spot-vectorizing float3 math with SSE and NEON intrinsics to restructuring loops for compiler auto-vectorization.
Anukari now runs on the CPU with hand-coded SIMD instead of the GPU. Part 1 explains the GPU origin story and the naive port that was only 5x slower.
The Radeon gfx90c driver aborts in clBuildProgram because it can't index kernel argument arrays dynamically. Moving them to constant memory fixed it.
Jul 2025
Multichannel 50x50 audio I/O with near-zero overhead, ASIO support on Windows, and a workaround for a Radeon clBuildProgram crash on gfx90c.
With Apple's help I cut Metal kernel launch overhead under 50us using MTLSharedEvent and double-buffered encoding, then had to unbreak CUDA.
May 2025
Applying Apple's NDA guidance to the GPU spin loop, serializing its kernels with MTLEvent, and deduplicating it across processes via shared memory.
My Appeal to Apple post worked. I got a call with a Metal engineer, performance hints I can use now, and an open line to the right people at Apple.
macOS GPU clock heuristics don't recognize real-time audio work, and my spin loop workaround fails on Pro and Max chips. I need the Metal team's help.
An undocumented Metal error 14 with multiple plugin instances traced to kernels clearing 300 MB delay buffers that a low-watermark check made unnecessary.
Feb 2025
GarageBand silently stops calling ProcessBlock, so Anukari now detects the auto-bypass and hands the physics simulation to a background thread.
A minimax optimizer now packs Anukari's 11 entity types into 32 GPU warps to minimize branch divergence. Huge presets run up to 2x faster.
Nov 2024
The CUDA port is done with all goldens passing. Native 1024-thread blocks beat OpenCL's 256-thread cap, so big presets no longer double their latency.
MacOS won't up-clock the GPU for latency-sensitive audio, so Anukari now burns one warp on useless spin work. Latency dropped about 40 percent.
Metal profiling shows the simulation is ALU-bound, so I'm chasing half floats and signed indexes, plus a visual style doc for hiring 3D artists.
Random glitches on the Filament Metal backend came down to render passes without a color clear. Enabling clearing fixed it and I filed an upstream bug.
Oct 2024
Ableton's Auto-Scale Plug-In Window option sent me down the Windows DPI awareness rabbit hole and into a Vulkan swap chain scaling driver bug.
Filament now draws my Blender models as instanced .glb assets and gives me shadows and ambient occlusion for free. Asset caching is next.
Sep 2024
The new renderer runs on macOS via Metal and an NSView overlay, with OpenGL fully removed. The macOS audio performance mystery remains unsolved.
After a dead end with WS_EX_LAYERED transparency, I'm drawing the 3D graphics in an HWND on top of the JUCE GUI, and native popup menus still appear.
Getting Filament rendering into a JUCE window is harder than expected since JUCE hides its swap chain, and overlay native windows break menus.
On macOS the 3D graphics interfere with GPU audio even when nothing is drawn, so I'm starting the Filament port to rule out Apple's OpenGL.
The OpenCL kernel now compiles and runs under Metal via macros and passes the golden tests, though the rough port still leaks memory everywhere.
Split the simulator into a shared base with OpenCL and Metal children. Macros may let the same kernel source compile for OpenCL, Metal, and CUDA.
The GPU copy optimization landed well, and NVIDIA on Windows runs big presets fine, but MacOS OpenCL stays mysteriously memory-bound. Metal port is next.
Aug 2024
Moving final microphone mixing onto the GPU should slash CPU-GPU copy bandwidth, my plan for the Mac performance problems pre-alpha testers uncovered.
Voice instancing works and it's better than I hoped. Time dilation retunes a full physics sim per note, and parallel GPU voices add zero slowdown.
Jul 2024
With code signing done and the macOS port shelved for now, I'm back on voice-instanced physics, running parallel instrument copies in OpenCL.
Golden tests now compare audio via chunked FFTs and L2 distance, which surfaced an OpenCL bug on Mac where objects can legally live at address NULL.
Jun 2024
After cleaning up the macOS port hacks and re-verifying Windows, Anukari now runs fully on my M1 MacBook, though the golden tests need fuzzy matching.
JUCE resists testable apps, so on macOS I moved all the unit tests inside a full JUCEApplication, trading test isolation for tests that pass.
Back from paragliding and porting unit tests to MacOS, which forced a cleaner cross-platform approach to GUI testing than my hacky Windows-only setup.
Anukari finally builds and links on my M1 Macbook after homebrew Clang pain, though the OpenCL code crashes whenever a microphone or modulator appears.
Two voice instances now run in parallel GPU work groups and pass the golden tests. Links stay shared in memory, so only mutable entities duplicate.
May 2024
Most of the CPU-side refactor for the new voice instancing memory layout is done, with golden tests catching every break in the CPU-to-GPU data reshuffle.
Breaking ground on instanced voice mode, which turns any instrument polyphonic by using time dilation for tuning. Prototype first, design later.
A fuzz test exposed OpenCL error -44 failures caused by out-of-bounds GPU memory access that persisted across teardown, apparently a driver bug.
Worked out every combination of invert, exponential, and multiply on modulator links, then added an exhaustive test proving CPU and GPU modulation match.
Apr 2024
LFO retriggering now works via the generalized MIDI note routing, and unit tests caught a dangling route left behind by deleted LFOs.
Mar 2024
Despite a cluster headache, the MIDI note picker works, and note routing is being generalized from hard-coded Exciters to any entity for LFO retrigger.
While building a golden test for the tempo-synced LFO I caught a MIDI bug where note off and on in the same audio block always ran as on then off.
A leftover OpenCL map with CL_MAP_WRITE_INVALIDATE_REGION corrupted my PRNG seeds and made the audio nondeterministic. A pause-toggle test caught it.
Golden tests now render a preset and MIDI clip to audio and diff against a verified .flac, so optimizations and GPU ports can't silently break the sound.
Master output level meters and a GPU meter are in. The GPU meter shows the share of the latency budget each block eats, like Ableton's CPU meter.
Feb 2024
No usable OpenCL obfuscator exists, so I wrote one in about 100 lines of Python with libclang. It renames symbols and keeps line numbers intact.
Delay lines work now, but sensor buffer indices must stay stable across delete and undo so a delay never plays back another sensor's old audio.
Jan 2024
Tracing a delay line bug to CL_WRITE_MAP_INVALIDATE_REGION skipping the DMA read on pinned memory, so stale data landed in the internal sample buffers.
Instead of a new entity type, delay lines reuse the AudioSignal exciters via a DelayLine link, with GPU audio moved into ring buffers.
After deleting everything down to a 5-line sine generator, The Bug turned out to live in my Focusrite Scarlett drivers, not in Anukari at all.
The Bug strikes every 19 seconds, but only on some launches, and it survives replacing all the physics with a pure sine wave. Nothing adds up yet.
Dec 2023
With no repro for The Bug, I beefed up the fuzz tests and hardened the GPU code against inf and NaN, hoping to rule out causes along the way.
After a jam session made distortion problems obvious, I built a GPU compressor for the microphones so live experimenting stays clean.
Found a cheap way to modulate rotation by restricting it to the Y axis for exciters and mics, and pushed panning modulation down to the GPU for free.
Sample and hold exposed how non-random my GPU noise PRNG was. I replaced the linear congruential generator with xorshift64* after a Galois LFSR detour.
Phase-state oscillators fixed retrigger dings, and gain modulation moved from linear space to decibels, worth the pow() calls on the GPU.
New UX explains dependent GPU memory limits, so maxing out masses visibly cuts your microphone budget instead of failing mysteriously.
Tens of thousands of random presets now get serialized to GPU format and simulated in a fuzz test, proving the new warp alignment code doesn't crash.
Padding GPU memory so each warp runs a single entity type cut kernel latency 25 to 50 percent and made performance far more stable.
Modulation values now reach the GUI, so a mic driven by two LFOs visibly circles in the 3D view. CPU-latched parameters like mallet hardness work too.
FM finally works on LFOs and oscillators after I dropped my stateless GPU waveform trick for phase-incrementing state, which turned out faster anyway.
A free-running LFO now computes on the GPU, but its stateless design means the value never lands in memory, so GUI animation needs a per-block write-back.
Modulators can now modulate springs on the GPU, including modulators modulating other modulators. Basic LFOs and a demo video come next.
Modulators can now link to springs, with groundwork for modulating modulators. Fuzz testing caught bugs in the new code and old undo/redo paths.
Nov 2023
To let modulators drive spring stiffness the Link class itself becomes Linkable, kept safe by an invariant allowing one layer of recursion.
Modulators are becoming their own 3D entities with routing stored on links, plus a JUCE crash fix upstream and more polish on my ADC23 slides.
Oct 2023
The Audio Units logo and the Audio Units symbol are trademarks of Apple Computer, Inc.
VST is a trademark of Steinberg Media Technologies GmbH, registered in Europe and other countries.





.jpg)