Captain's Log: Stardate 78354.7
As I mentioned in the previous post, I've been working on writing a better algorithm for optimizing the way that entities are aligned to GPU warps (or as Apple calls them, SIMD-groups). For the sake of conversation, let's assume that each GPU threadgroup is 1024 threads, and those are broken up into 32 warps, each of which has 32 threads. (These happen to be actual numbers from both my NVIDIA chip and my Apple M1.)
Each warp shares an instruction pointer. This is why Apple's name for them makes sense: each SIMD-group is kind of like a 32-data-wide SIMD unit. In practice these are some pretty sophisticated SIMD processors, because they can do instruction masking, allowing each thread to take different branches. But the way this works for something like "if (x) y else z" is that all the SIMD unit executes instructions for BOTH y and z on every thread, but the y instruction is masked out (has no effect) for threads that take the z branch, and z is masked out for threads that take the y branch. This is not a huge deal if y and z are simple computations, but each branch has dozens of instructions, you have to wait for each branch to be executed in serial, which is slow.
Note that this penalty is only paid if there are actually threads that take both branches. If all the threads take the same branch, no masking is needed and things are fast. This is the key thing: at runtime, putting computations with similar branch flows in the same warp is much faster than mixing computations with divergent branch flows.
For Anukari, the most obvious way to do this is to group entities by type. Put sensors in a warp with other sensors, put bodies in a group with other bodies, etc. In total, including sub-types, Anukari has 11 entity types. This means that for small instruments, we can easily sort each entity type into its own warp, and get huge speedups. This is really the main advantage of porting from OpenCL to CUDA: just like Apple, NVIDIA artificially limits OpenCL to just 8 32-thread warps (256 threads). If you want to use the full 32 32-thread warps (1024 threads), you have to port to the hardware's native language. Which, we really do, because with OpenCL's 8 warps, we're much more likely to have to double-up two entity types in one warp. Having 32 warps gives us a ton of flexibility.
The Algorithm
So we have 11 entity types going into 32 buckets. This is easy until we consider that an instrument may have hundreds of one entity type, and zero of another, or that instruments might have 33 of one entity type, which doesn't fit into a single bucket, etc. What we have here is an optimization problem. It is related to the bin-packing problem, but it's more complicated than the vanilla bin-packing problem because there are additional constraints, like the fact that we can break groups of entities into sub-groups if needed, and the fact that it needs to run REALLY fast because this happens on the audio thread whenever we need to write entities to buffers.
I'm extremely happy with the solution I ended up with. First, we simplify the problem:
- Each entity type is grouped together into a contiguous unit, which might internally have padding but will never be separated by another entity type.
- We do not consider reordering entity types: there is a fixed order that we put them in and that's it. This order is hand-chosen so that the most expensive entities are not adjacent to one another, and thus are unlikely to end up merged into the same warp.
A quick definition: a warp's "occupancy" will be the number of distinct types of entities that have been laid out within that warp. So if a warp contains some sensors, and some LFOs, its occupancy would be 2.
The algorithm then is as follows:
- Pretend we have infinite warps, and generate a layout that would be optimal. Basically, assign each entity type enough warps such that the maximum occupancy is 1. (This means that some warps might be right-padded with no-op entities.)
- If the current layout fits into the actual amount of warps the hardware has, we are done.
- If not, look for any cases where dead space can be removed without increasing any warp's occupancy. (On the first iteration, there won't be any.)
- Increment the maximum allowable occupancy by 1, and merge together any adjacent warps that, after being merged, will not exceed this occupancy level.
- Go back to step 2.
That's it! This is a minimax optimizer: it tries to minimize the maximum occupancy of any warp. It does this via the maximum allowable occupancy watermark. It tries all possible merges that would stay within a given occupancy before trying the next higher occupancy.
There are a couple of tricks to make this efficient, but the main one is that at the start of the algorithm, we make a conservative guess as to what the maximum occupancy will have to be. This way, if the solution requires occupancy 11 (say there are 1000 bodies and 1 of each remaining entity type, so the last warp has to contain all 11 types), we don't have to waste time merging things for occupancy 2, 3, 4, ... 11. It turns out that it's quite easy to guess within 1-2 occupancy below the true occupancy most of the time. I wrote a fuzz test for the algorithm, and in 5,000 random entity distributions the worst case is 5 optimizer iterations, and that's rare. Anyway, it's plenty fast enough.
The solutions the optimizer produces are excellent. In cases where there's a perfect solution available, it always gets it, because that's what it tries first. And in typical cases where compromise is needed, it usually finds solutions that are as good as what I could come up with manually.
Results
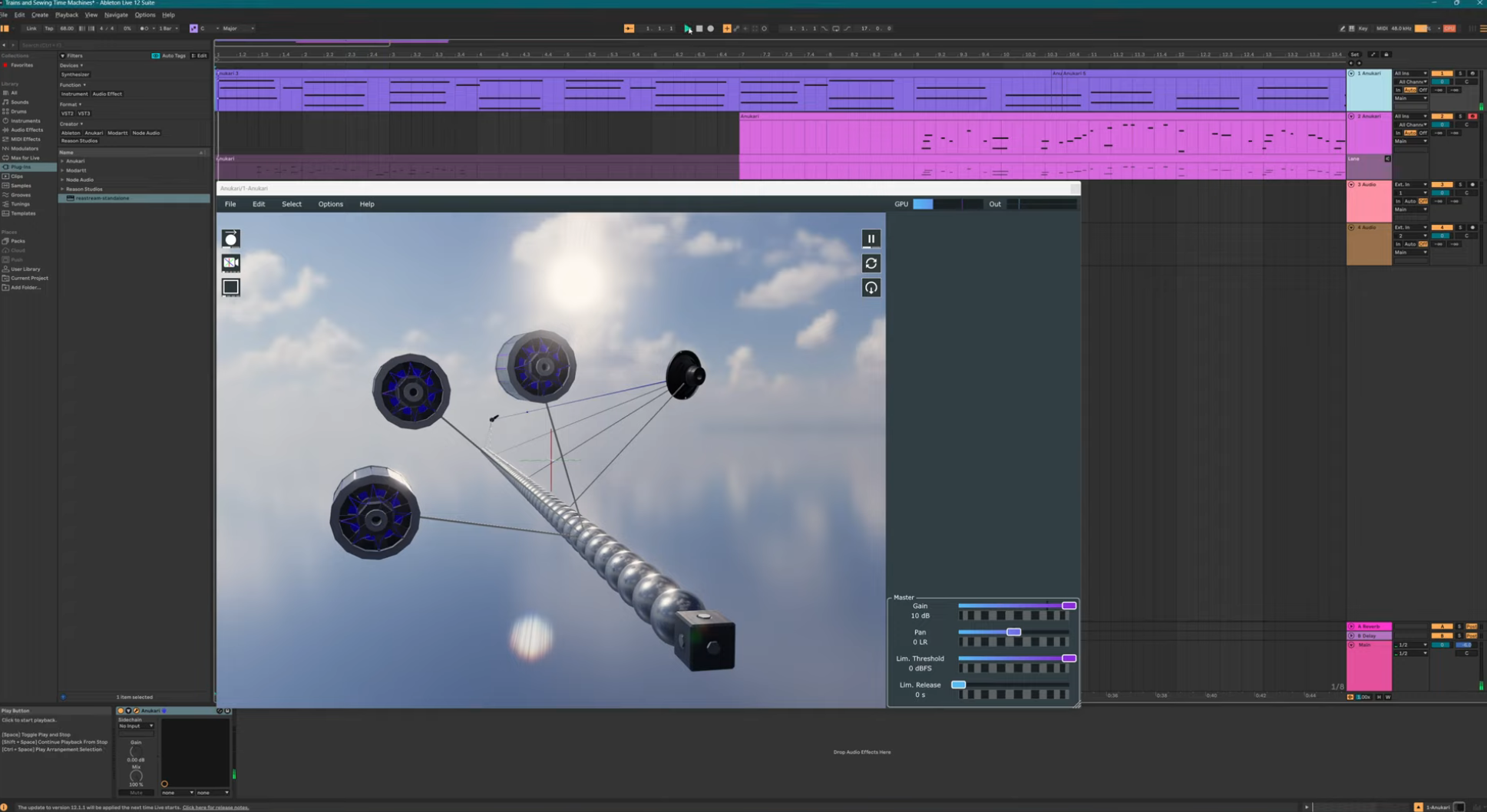
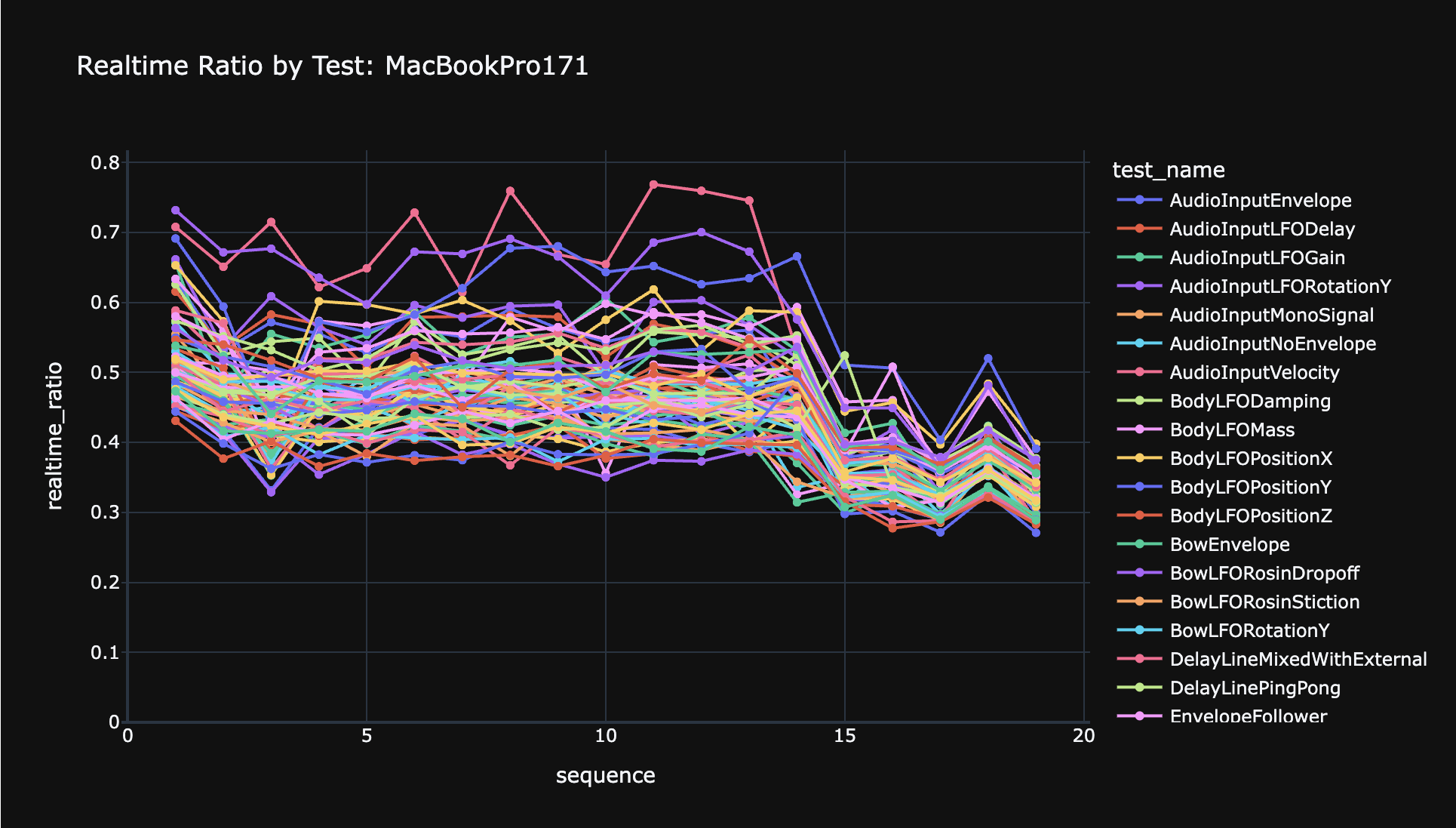
That's all fine and good, but does it work? Yes. Sadly I don't have a graph to share, because this doesn't help with all my microbenchmarks. Those are all tiny instruments for which the old optimizer worked fine.
But for running huge complex instruments, it is an ENORMOUS speedup, often up to 2x faster with the new optimizer. For example, for the large instrument in this demo video, it previously was averaging about 90% of the latency budget, with very frequent buffer overruns (the red clip lines in the GPU meter). That instrument is now completely usable with no overruns at all, averaging maybe 40% of the latency budget. Other benchmark instruments show even better gains, with one that never went below 100% of the latency budget before now at about 40%.
This opens up a TON more possibilities in terms of complex instruments. I think at this point, at least on Windows with NVIDIA hardware, I am completely satisfied with the performance. Apple with Metal is almost there but still needs just a tiny bit more work for me to be satisfied.





.jpg)