Captain's Log: Stardate 78809.2
[EDIT]: Apple got in touch! Details here.
TL;DR: To make Anukari’s performance reliable across all Apple silicon macOS devices, I need to talk to someone on the Apple Metal team. It would be great if someone can connect me with the right person inside Apple, or direct them to my feedback request FB17475838 as well as this devlog entry.
This is going to be a VERY LONG HIGHLY TECHNICAL post, so either buckle your seatbelt or leave while you still can.
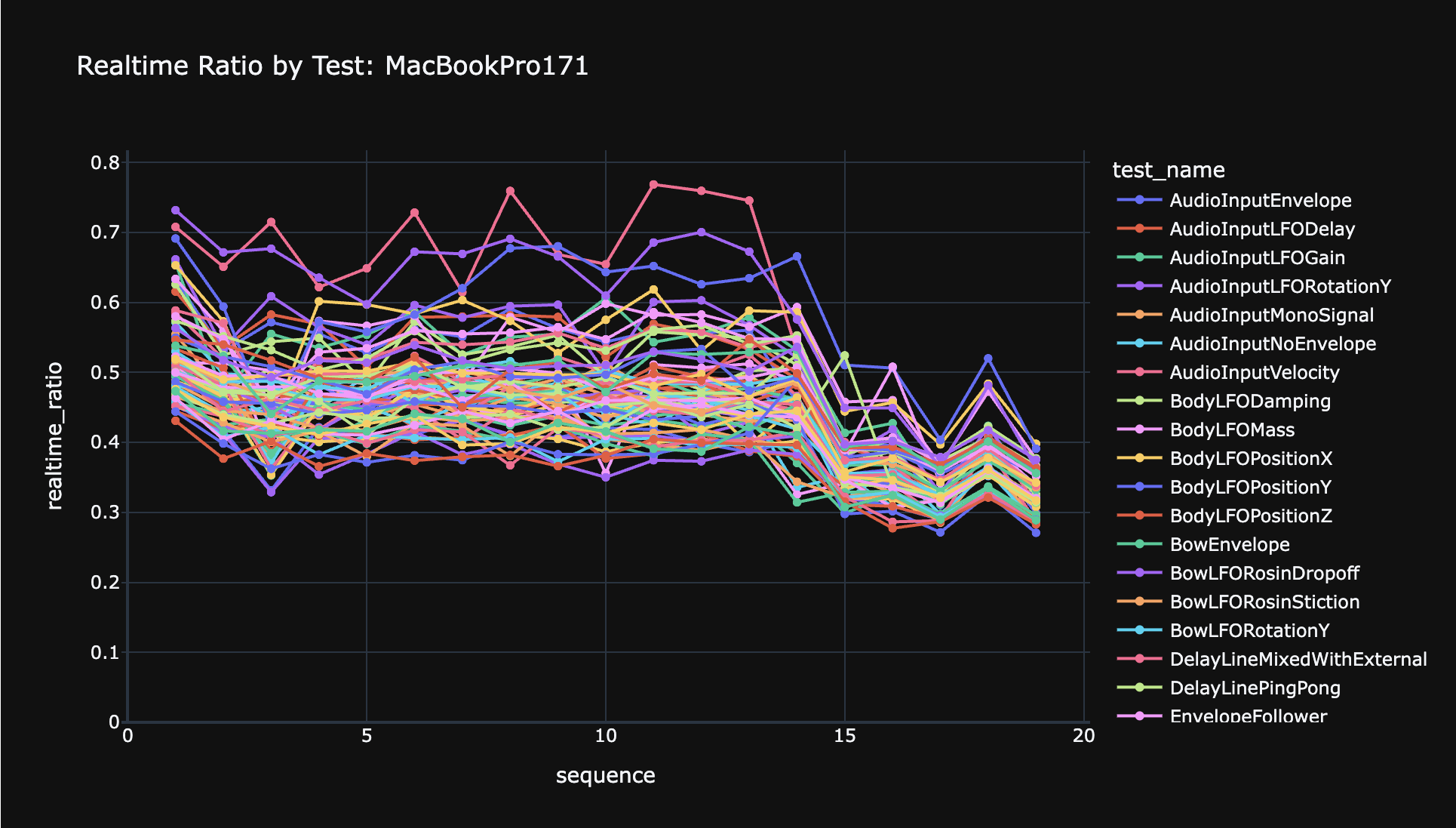
The Anukari 3D Physics Synthesizer simulates a large spring-mass model in real-time for audio generation. To support a nontrivial number of physics objects, it requires a GPU for the simulation. The physics code is ALU-bound, not memory-bound. All mutable state in the simulation is stored in the GPU’s threadgroup memory, which is roughly equivalent to a manually-allocated L1 cache, so it is extremely fast.
The typical use-case for Anukari is running it as an AudioUnit (AU) or VST3 plugin inside a host application like Pro Tools or Ableton, also called a Digital Audio Workstation (DAW). The DAW invokes Anukari for each audio buffer block, which is a request to generate/process N samples of audio. For each block, Anukari invokes the physics simulation GPU kernel, waits for the result, and returns.
The audio buffer block system is important because GPU kernel scheduling has a certain amount of latency overhead, and for real-time audio we have fixed time constraints. By amortizing the GPU scheduling latency over, say, 512 audio samples, it becomes negligible. But the runtime of the kernel itself is still very important.
Apple’s macOS is obviously extremely clever about power management, and Apple silicon hardware is built to support the OS in achieving high power efficiency.
As with all modern hardware, the clock rate for Apple silicon chips can be slowed down to reduce power consumption. When the OS detects that the processing demand for a given chip is low (or non-existent), it can decrease the clock rate for that chip. This is awesome.
The problem is that due to the way Anukari runs inside a DAW and interacts with the GPU, the heuristics that macOS uses to determine whether there is sufficient demand upon the GPU to increase its clock rate do not work.
Consider the chart below. The CPU does some preparatory work, there’s a small gap which represents kernel invocation latency, and then the GPU does a large block of work. Finally there’s another small gap representing the real-time headroom.

I don’t have any real knowledge of macOS’s heuristics for deciding when to increase the GPU clock speed, but I might reasonably guess that it relies on something like the load average. In the diagram above, the GPU load average might be only 60%, because between audio buffer blocks it is idle. Perhaps this does not meet the threshold for increasing the GPU clock rate.
But this is terrible for Anukari, because to meet real-time constraints, it needs the absolute lowest latency possible, which requires the highest GPU clock rate. I’m not sure how low the Apple GPU clock rate can go, but it definitely goes low enough to make Anukari unusable.
To be clear, it’s pretty understandable that macOS handles this situation poorly, because the GPU is mostly used for throughput workflows like graphics or ML. Audio on the GPU is really new, and there are only a couple of companies doing it right now.
Oh yes. Thankfully, Apple’s first-part Instruments tools that come with Xcode have a handy Metal profiler. Among other things, this is how I first learned that Anukari is ALU-bound.
The Metal profiler has an incredibly useful feature: it allows you to choose the Metal “Performance State” while profiling the application. This is not configurable outside of the profiler. This is how I first figured out that the GPU clock rate was the issue: Anukari works perfectly under the Maximum performance state, and abysmally under the Minimum performance state.
Given the explanation above, this is a great question. Most people with macOS find that Anukari works great. For example, I intentionally bought a base-model Macbook M1 for development, so that if Anukari worked well for me, I’d know it worked well for people with beefier hardware.
So how is it that Anukari works great on macOS for most people? Well, as Steve Jobs said, “It’s better to be a pirate than to join the Navy.”
Without being able to rely on macOS to do the right thing, I thought like a pirate and came up with a workaround: in parallel with the audio computation on the GPU, Anukari runs a second workload on the GPU that is designed to create a high load average and trick macOS into clocking up the GPU. This workload is tuned to use as little of the GPU as possible, while still creating a big enough artificial load to trigger the clock heuristics.
In other words, it runs a spin loop to heat up the GPU. On my Macbook M1, this completely solves the issue. Anukari runs completely reliably. I called this strategy “waste makes haste” and it is documented in detail on my devlog here.
To be clear, the spin loop is an unholy abomination and I hate that it’s necessary. But it is absolutely required for Anukari to work well for macOS users. And for most macOS users, it works great.
Like I said, on my M1 things work perfectly. But then I released the Anukari Beta and some macOS users are having problems. What’s different?
First: I’m not certain. But I have a couple hypotheses.
Weirdly, it appears that most users with performance issues are using Pro or Max Apple hardware. These have additional GPU chiplets. I am completely speculating here, but Apple’s hardware is amazing so it stands to reason that each GPU chiplets's clock rate can be changed independently. Do you see where this is going?
If macOS is really smart, it should see that Anukari is running two independent GPU workloads: the physics kernel, and the spin kernel. Why not run those on separate GPU chiplets? That’s smart. And then, if I’m right that the GPU chiplets have independent clock rates, well, Anukari is hosed because the stupid spin workload will get a fast-clock GPU and the audio workload will get a slow-clock GPU.
I could be wrong. Another possibility is that the GPU has a single clock rate, and my spin workload is too conservative to convince the much more powerful GPU to clock up. Maybe my spin kernel can heat up an M1 GPU but not an M4 Pro GPU, because the M4 Pro is faster.
Apple engineers will obviously know better than I do here, but I’ll present a couple of obvious possibilities.
Solution 1: On macOS, audio processing is done on a thread (or group of threads) called an Audio Workgroup. These are explained in Apple’s documentation here. Within an Audio Workgroup, the OS understands that the threads have real-time constraints, and prioritizes those threads appropriately. This is actually a fantastic innovation, because before Audio Workgroups, it wasn’t really possible to do real-time audio processing safely across multiple threads without problems like priority inversion, etc.
The Audio Workgroup concept could be extended to cover processing on the GPU. Any MTLCommandQueue managed by an Audio Workgroup thread could be treated as real-time and the GPU clock could be adjusted accordingly.
Solution 2: The Metal API could simply provide an option on MTLCommandQueue to indicate that it is real-time sensitive, and the clock for the GPU chiplet handling that queue could be adjusted accordingly.
Solution 3: Someone could point out that I'm an idiot and there's already some way to get what I want, and this whole post was a waste of my time. This would be wonderful.
Game Mode certainly seems similar to what Anukari needs. However, Game Mode is at the process-level, and Anukari is mostly used as a plugin inside other processes, which don’t support Game Mode, and anyway Anukari has no control. Also Anukari is usually not fullscreen, which Game Mode requires.
Not a problem at all. I don’t know if it’s because Windows gives users more control over their system’s performance state, or if e.g. NVIDIA drivers are less careful about power consumption, or what. But the spin loop is not necessary on Windows.
It's not a great look for Apple that a Windows PC with a pretty wimpy GPU can run Anukari just fine, and the most expensive Mac M4 Max stutters, because obviously Apple's hardware is incredible and just needs to be let off the leash a bit.
For a throughput workload, this is exactly what I’d do. But Anukari is not throughput-sensitive, it is latency-sensitive.
The idea with pipelining is that maybe Anukari could schedule multiple physics simulation kernels in advance, so that the GPU could be processing the current audio sample block at the same time that the CPU is preparing the next block for the GPU. (This would also alleviate the kernel invocation latency overhead, but that’s not as important.)
But anyone who understands pipelining knows that it increases throughput at the cost of latency. Anukari processes audio in real-time, so each kernel invocation needs access to the real-time audio input data (e.g. from the microphone). Thus Anukari can’t do something like speculative execution where it processes the next audio block early, because it wouldn’t have the input data required to do so.
This solution might fix the problem where the spin and physics kernels end up running on separate GPU chiplets (if that is indeed the issue).
I have tried this, actually. The reason it doesn’t work is again because Anukari is latency-sensitive. What happens is that sometimes the spin kernel runs a little too long and cuts into the time for running the physics kernel. I experimented with small spin kernels, using volatile unified memory to allow the CPU to write an “exit kernel early” flag. Even with these hijinx, sometimes the spin kernel cut into physics kernel time.
In distributed systems, such as databases, this is known as “request hedging,” and it can reduce tail latency and latency variance quite a bit. And in the case of Anukari, the extra copies, or hedges, would conceivably serve the purpose of providing load on the GPU to get the OS to increase the performance state.
We’ll call this GPU kernel hedging, and it would look something like the chart below:
In this example, for each audio block, 3 copies of the physics kernel are launched. For the first audio block, the result from GPU1 would be used because it is the first kernel to finish. For the second audio block, the result from GPU2 would be used. In both cases, the audio data would be returned to the host application before the other copies of the kernel finish.
Unfortunately there are a couple of reasons that this won’t work for Anukari.
The main issue has to do with what happens when one of the physics kernels takes more than one full audio block cycle to complete. In the diagram above, this happens with GPU3: it has not completed by the time the second audio block is requested. In the diagram, all the kernels started executing at the same time, but in reality it’s possible that the slowest kernels will be ones that the OS took a long time to schedule. It’s entirely possible that one of the hedged kernel streams will fall behind by several audio blocks.
So for a future audio block, somehow we will need to “catch up” any kernel streams that fell behind. This requires some kind of fast-forward, since we can’t wait for them to catch themselves up. To do that, we can simply copy the internal state from another kernel stream that is already caught up.
The problem is that this copy is expensive. The largest internal state that Anukari stores is the audio buffer used for delay lines. It stores 1 second of historical audio for every mic. This buffer’s size is 48,000 audio samples * 50 mics * 2 channels (L/R) * 16 voices * 4 bytes per float = 307 MB. And of course it’s larger at higher sample rates.
To do this efficiently we’d need to keep precise records of what parts of the sample buffer are “dirty” for each hedged kernel stream, and copy only the dirty parts. In practice, though, this will not be efficient because the memory layout for this buffer is heavily optimized to be fast for the particular read workload that the physics kernel performs. This means that even if the fast-forward copy was precise about copying only the minimum amount of data, it would be scattered about across the entire buffer. This copy will be slow. Furthermore, the internal delay line audio buffer is just one of several buffers that would need to be synchronized.
Another issue is that whenever the user changes the model, those changes would need to be fanned out to all the hedged kernels.
The final problem here is that the physics kernel has a substantially larger GPU footprint than the “waste makes haste” spin kernel, which is designed to have the smallest footprint that can reliably warm up the GPU. So kernel hedging would impose more wasted load on the GPU, reducing the number of Anukari instances that can be run in parallel, or even worse, causing competition between hedge kernels that leads to them all running more slowly.
Because the simulation is ALU-bound, there’s not much performance to be gained from the typical optimization low-hanging fruit: improving memory access patterns. To speed up Anukari’s physics kernel, the only thing that really helps is optimizing arithmetic throughput. For example, Anukari uses FP16 math where possible to better-saturate Apple’s ALUs. Instructions have been reordered using micro-benchmarks. All physics state is in L1 memory. Loads are reordered for vectorization. The list goes on.
Furthermore, Anukari heavily exploits the fact that threads within Apple’s SIMD-groups (roughly) share an instruction pointer. Different physics objects have highly divergent code branch paths, so simulating two types of objects within a SIMD-group is slow due to the requirement for instruction masking while the top-level branch paths are executed serially. To avoid this, Anukari dynamically optimizes the memory layout of physics objects to minimize the number of object types executed within each SIMD-group. This optimization is described here in great detail, and is a massive performance win.
What I'm trying to say is that I have bent over backwards to squeeze every last drop of performance out of Apple's hardware. It's been fun to do!
There are further arithmetic optimizations to be done, but they will be fairly marginal. We’re talking single-digit percentage point speedups. Anukari’s GPU code is already VERY FAST. If you’re curious, there’s more info on Anukari’s optimizations here.
On powerful machines, Anukari can simulate 768 - 1024 physics objects. Each object can be arbitrarily connected to other objects, meaning that they influence one another. Each object has to be stepped forward in an implicit Euler integration at the audio sample rate, typically 48,000 samples per second. Each object has somewhere between 3 and 10 parameters that affect its behavior. Some of the behaviors involve expensive math, like vector rotation, exp(), log(), etc. Oh, and on top of that all, Anukari runs up to 16 entire copies of the physics simulation in parallel for polyphony!
This is simply not even close to feasible on the CPU! Trust me, I tried. It’s not even a little bit close. The GPU just has a ridiculous number of ALUs, it gives me explicit control over the L1 cache layout, and the concurrency constructs like threadgroup_barrier allow the physics integration steps to be done massively in parallel without consistency issues, without expensive CPU mutexes.
I’ll say it again: Anukari does not exist without GPU processing.
Maybe they shouldn’t, I don’t know. Anukari is a tiny startup. It’s a niche product. It’s doing something weird.
On the other hand, the people who like Anukari really like it. Mick Gordon, the composer for IMO the greatest DOOM games of all time, randomly showed up and blew everyone away with an incredible demo using Anukari. Anukari is receiving praise from people who really love synthesizers like CDM. Comments have appeared on random internet threads that I didn't start, like, "it's the most creative plugin I've tried in the last 10 years.
But mostly, Anukari is using Apple’s hardware in what I consider an incredibly cool way, allowing users to do something that they’ve never been able to do before. And Apple’s hardware is completely up to the task. But it just needs a little push in the right direction.
I don’t really want to include this last question, but it is here to address the fact that the CEO of GPU Audio, Alexander Talashov, likes to drive by threads about Anukari and suggest that if Anukari used his APIs it would solve our problems. I would be so happy if this were true.
Alexander is a great guy, and his product (GPU Audio) is a great product. I’ve met him in person, and he’s incredibly passionate about making the GPU accessible for DSP. Audio folks should check it out, it’s really cool. I wish GPU Audio huge success, and support their product.
But… GPU Audio has nothing useful for Anukari. Fundamentally the problem is that Anukari is not anything like a traditional DSP application. It’s a numerical differential equation integrator, far more similar to a video game physics engine than a DSP application. Sure, there are bits and bobs of DSP inside the physics engine, for example Anukari’s mics in the physics world do have compression, and that’s done in-line with the physics calculations on the GPU. But the vast majority of computation is Eulerian integration.
It needs to be understood that I’m programming the GPU at the bare Metal layer (yes pun intended), and am taking advantage of a number of hardware features and ridiculous domain-specific optimizations that are quite necessary to make this work. And all I need is for Apple to reliably turn up the clock rate on the GPU.


Captain's Log: Stardate 78674.7
Evan Mezeske
Mar 2025
Captain's Log: Stardate 78275.5
Evan Mezeske
Oct 2024

Captain's Log: Stardate 78006.4
Evan Mezeske
Jul 2024



.jpg)