Yesterday I pushed out a 0.9.6 pre-release version of Anukari that has some extremely promising performance improvements for macOS. On my local test machines, it's working flawlessly, but I'm hesitant to declare victory until I hear back from a few more users.
A big thank you to Apple
I am not an Apple shill. Some of my past devlog entries show some, shall we say, "mild frustration" with Apple.
But I want to give credit where credit is due, and Apple has been incredibly over-the-top helpful with Anukari's performance problems.
The specific engineers I've been speaking with have been slammed with prep work for WWDC, and I know what that's like from working at Google when I/O is coming up. Yet they still have spent an inordinate amount of time talking to me, answering questions, etc. So: Apple folks, you know who you are, and thank you!
The especially good news here is that Apple isn't just spending this time with me to make Anukari work well, but is using this as an opportunity to improve the Metal APIs for all similar latency-sensitive use cases. I got lucky that I was in the right place at the right time, and Apple saw an opportunity to work super closely with an outside developer who cared a LOT about latency.
Lower-latency kernel launches and waits
Based on Apple's help up to this point, the GPU performance state problems I was having are no longer an issue. But there were still some cases where I was not satisfied with Anukari's macOS performance.
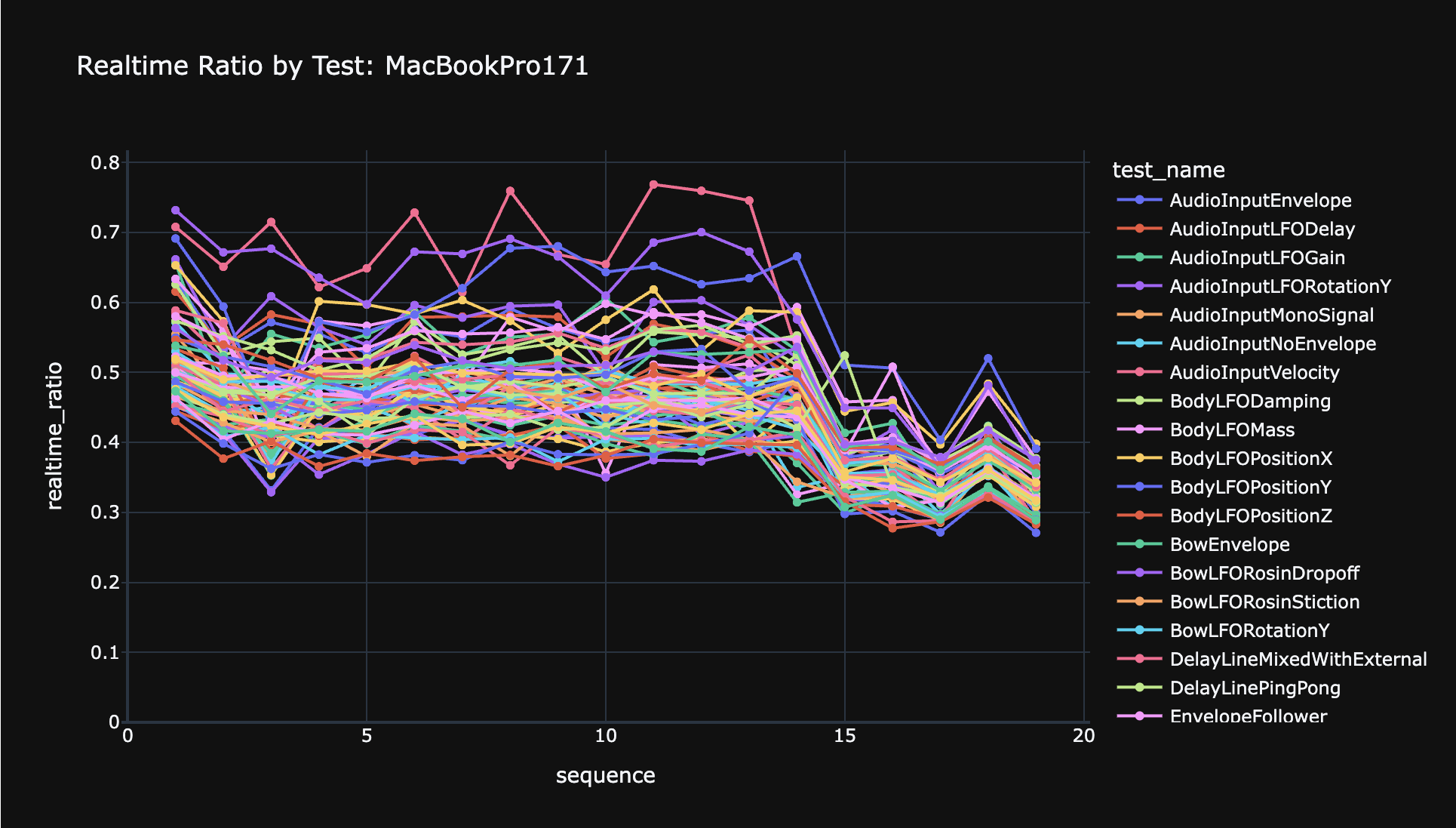
Using Metal's GPU timestamps, I came to the conclusion that while the actual runtime of the kernel is pretty stable now. The GPU is in a consistent performance state, and the GPUEndTime - GPUStartTime duration is also consistent.
However, looking at the end-to-end duration of encoding the MTLCommandBuffer, to telling the kernel to launch (MTLCommandBuffer commit), to receiving the results back on the CPU (MTLCommandBuffer waitUntilCompleted), it was a bit longer than I'd like, but more importantly it was really inconsistent. There was a lot of jitter.
I spoke with an Apple engineer, and they suggested that I try using MTLSharedEvent to trigger both the launch of the kernel, as well as to wait for the result. Basically the idea was to do the encoding work for the next command buffer on the CPU while waiting for the previous one to finish. The next buffer would include a command to block for an event before starting the kernel, and a command to signal another event after it finished.
The part about doing the encoding work while waiting for the previous buffer is a no-brainer. The encoding work takes around 50us and all of that can be saved by doing it in parallel with the GPU work. I had considered this before, but at that time 50us was not worth the effort. Now, though, I've cut out so much other slack that it was worth it. There was a bit of complexity having to do with parameters for the kernel that are unknown at the time of encoding -- these had to move to buffers that get written later when the parameters become known. But overall this was pretty straightforward.
However the part about using an MTLSharedEvent waitUntilSignaledValue for the CPU to block on kernel completion didn't seem as obvious to me. Using MTLCommandBuffer waitUntilCompleted seemed like basically the same thing to me. But implementing this was even easier than the command double-buffering, so of course I tried it out. And I'm glad I did, because as Apple predicted, it had much lower latency. Clearly the OS/firmware services these two blocking calls in different ways, and for whatever behind-the-scenes reason, the MTLSharedEvent version works way better.
So I would definitely recommend to anyone trying to achieve super low-latency kernel launches: use MTLSharedEvent both to start the kernel and to wait for it to finish, and use double-buffering to prepare each command buffer on the CPU while the previous one is running on the GPU. It makes a big difference. I am now seeing < 50us of scheduling/waiting overhead.
But nothing is that simple
After making all these changes to improve Anukari's macOS performance, I went back to the CUDA backend on Windows and found that I had severely slowed it down. About 90% of the GPU code is shared between Metal/CUDA/OpenCL, so when I change things it often affects performance on all three backends in different ways. It's a bit like putting a fitted sheet on a bed -- you get one corner on, but then when you pull the next corner on, the previous corner slips back off.
(As an aside, this is the reason Anukari does not yet support Linux. It's a lot of work to deal with the fitted sheet issue for two platforms already. Linux support will come after Windows and macOS are super performant and stable.)
After some git bisecting, I found that the CUDA performance regression was caused by moving some of the kernel's parameters to a device memory buffer. This was part of moving the Metal implementation to encode the next command in parallel with the current one: parameters like the audio block size that aren't known until the next audio block is being processed can't be kernel parameters, but rather have to be written to device memory later, after the kernel has been committed but before the MTLSharedEvent is signaled to start kernel execution.
The kernel parameters in question are tiny, perhaps 64 bytes in total. On macOS this buffer is marked as immutable, and I saw zero performance degradation from having the kernel read it from device memory as opposed to receiving it as arguments.
However on CUDA, there was a huge performance loss from this change. Reading these 64 bytes of parameters from __constant__ device memory in every kernel thread caused the overall kernel to run 20-30% slower, as compared to passing the data directly as kernel parameters.
I ruled out the extra cuMemcpyHtoDAsync call for the new memory segment causing the increased latency. Careful timing showed that the extra time really was really in the kernel execution.
I don't know why this is so much slower, but I have a hypothesis, which is that when the constant data is passed via a kernel parameter, rather than __constant__ device memory, CUDA is capable of doing some kind of inlining that is otherwise not possible. For example, maybe it can rewrite some of the kernel instructions to use immediate operands instead of registers. Or possibly it is actually unrolling some loops at runtime. (Something to experiment with.)
Anyway the solution here was simply to bifurcate the GPU backends a little bit and have the CUDA backend pass the arguments directly to the kernel, rather than using a __constant__ buffer. This works just fine for now, but I may eventually need to find an alternative if I want to apply the same background encoding concepts that I've been successful with on Metal to the CUDA backend.
For now, things are fast again and I'm going to move on to some other work before taking a further pass at improving the CUDA backend. My findings here do suggest that there may be other CUDA optimizations possible by trying to move more data into direct kernel parameters instead of __constant__ buffers. Given the performance difference, I will definitely experiment with this.
And hey, some new features!
While performance is still my main focus, I did take a couple breaks from that to implement some new features.
The one that I'm by far the most excited about is that Anukari's modulation system now has a target called MIDI Note Trigger, which allows any object that can be triggered via MIDI notes to also/instead be triggered through modulation.
The way it works is that when a modulation signal goes from below 0.5 to above 0.5, that's a note on event. And when it drops from above 0.5 to below 0.5, that's a note off.
This is extremely simple, but it opens up a gigantic range of possibilities. LFOs can now trigger envelopes. Envelope triggers can now be used to delay note on events to create arpeggiator effects. Mallets can be triggered at insane speeds. Envelope followers can be used to trigger oscillators when an audio input signal gets loud enough. The list goes on.






.jpg)