Captain's Log: Stardate 78825.2
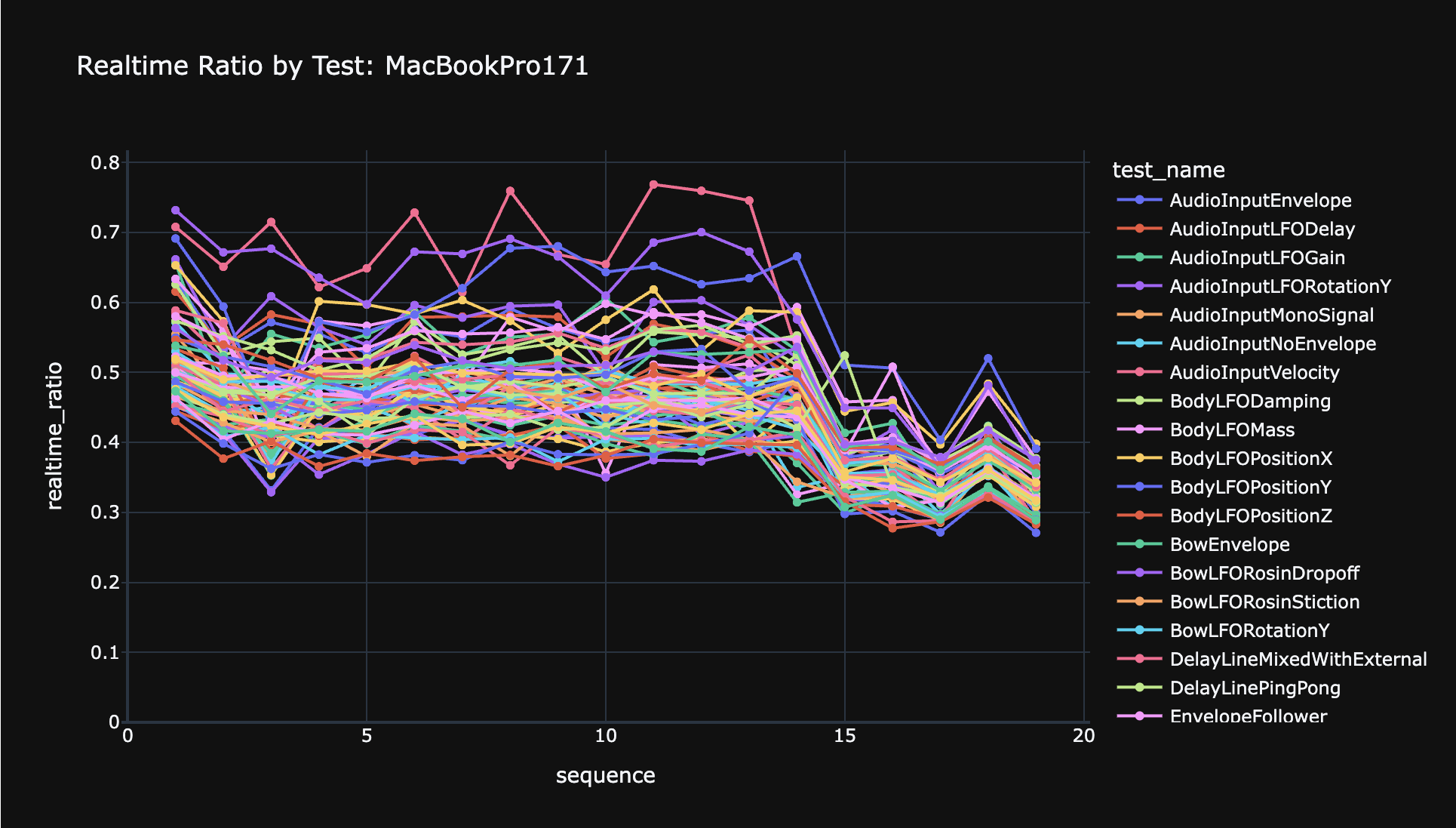
Since my last update, I've spent all my time trying to take advantage of the insights that the engineers on the Apple Metal team gave me with regards to how to convince the OS to increase the performance state such that Anukari will run super smoothly.
A big piece of news is that I bit the bullet and bought a used Macbook Pro M4 Max so that I can iterate on testing these changes much more quickly, and verify that the same tuning parameters work well on both my wimpy M1 Pro and my beastly M4 Max.
Things are working MUCH better now on the M4 Max. At least for me, I can easily run 6 plugin instances in Logic Pro with no cracking at all (512 buffer, 48 kHz). That said, there's still a weird issue that I've seen on my M1 Pro where sometimes a plugin instance will get "stuck" performing badly, and I don't know why. Simply changing the simulation backend to OpenCL and back to Metal fixes it, so it's something stateful in the simulator. More work to do!
Secret NDA stuff
One thing I've been doing is applying the details that Apple shared under NDA to tickle the OS performance state heuristics in just the right way. The nice thing here is that knowing a tiny bit more about the heuristics, I'm able to be much more efficient and effective with how I tickle them. This means that the spin loop kernel uses less GPU resources to get the same result, and thus it interferes less with the audio kernel, and uses less power. I think this is as much detail as I can go into here, but honestly it's not that interesting, just necessary.
Spin loop serialization
Separately from the NDA stuff, I ran into another issue that was likely partly to blame for the horrible performance on the most powerful machines.
The Apple API docs for MTLCommandBuffer/commit say, "The GPU starts the command buffer after it starts any command buffers that are ahead of it in the same command queue." Notice that it doesn't say that it waits for any command buffers ahead of it to finish. From what I can tell, Metal actually is quite anxious to run these buffers in parallel if it thinks that it's safe to do so from a data dependency perspective, and of course if there are cores available.
The spin loop kernel runs for a very short duration, and thus there's a CPU thread that's constantly enqueuing new command buffers with blocks of spin kernel invocations.
On my M1 Pro, it seems that the spin kernels that were queued up in these buffers ran in serial, or at least mostly in serial. But on my new M4 Max, it appears that the Metal API is extremely aggressive about running them in parallel, to the extent that it would slow down other GPU work during brief bursts of "run a zillion spin kernels at once."
The solution to this was very simple, and that was simply to use an MTLEvent to guarantee that the queued spin kernels run in serial.
Getting the spin loop out of the audio thread
The original design for the spin loop kernel was that one of the audio threads would take ownership of it, and that thread was responsible for feeding in the buffers of spin kernels to run. There's never any need to wait for the results of a spin kernel, so the audio thread was only paying the cost of encoding command buffers.
I built it this way out of sheer convenience — the audio thread had a MTLDevice and MTLLibrary handy, so it was easy to put the spin loop there. Also, errors in the spin loop were exposed to the rest of the simulator machinery which allows for retries, etc.
But that's not a great design. First, even if the encoding overhead is small, it's still overhead that's simply not necessary to force upon the audio thread. And because MTLCommandQueue will block if it's full, bugs here could have disastrous results.
So finally I moved the spin kernel tender out of the audio thread and into its own thread. The audio threads collectively use a reference-counting scheme to make sure a single spin loop CPU thread is running while any number of simulation threads are running. The spin loop thread is responsible for its own retries. This removes any risk of added latency inside the audio threads.
Inter-process spin loop deduplication
While I was rewriting the spin loop infrastructure, I decided to fix another significant issue that's been there since the beginning.
Anukari has always made sure that only a single spin loop was being run at a time by using static variables to manage it. So for example, if the user has 5 instances of Anukari running in their DAW, only one spin loop will be running.
But this has problems. For example, because Anukari and AnukariEffect are separate DLLs, they have separate static storage. That means that if a user has both plugins running in their DAW, that two spin loops would be run, because the separate DLLs don't communicate. This is bad, because any additional spin loops are wasting resources that could be used for the simulations!
Even worse, though, are DAWs that do things like run plugins in a separate process. Depending on how this is configured, it might mean that many spin loops are running at once, because each Anukari instance is in a separate process.
In the past I had looked at ways to do some kind of really simple IPC to coordinate across processes, and also across DLLs within the same process. But none of the approaches I found were workable:
- Apple's XPC: It's super heavyweight, requiring Anukari to start a spin loop service that all the plugins communicate with.
- POSIX semaphores: This would work except the tiny detail that they aren't automatically cleaned up when a process crashes, so a crash could leave things in a bad state that's not recoverable without a reboot.
- File locks (F_SETLK, O_EXLOCK): Almost perfect, except that locks are per-process, not per- file descriptor. So this would not solve the issue with the two DLLs needing to coordinate: they would both be able to acquire the lock concurrently since they're in the same process.
- File descriptor locks (F_OFD_SETLK): Perfect. Except that macOS doesn't support them.
Today, though, I found a simple approach and implemented it, and it's working perfectly, so that in the 0.9.5 release of Anukari, there is guaranteed to only ever be a single spin loop thread globally, across all processes.
It turns out the simplest way to do this was to mmap() a shared memory segment from shm_open(), and then to do the inter-process coordination using atomic variables inside that segment. I already had the atomic-based coordination scheme implemented from my original spin system, so I just transplanted that to operate on the shared memory segment, and voila, things work perfectly. The atomic-based coordination is described in the "Less Waste Still Makes Haste" section of this post.
The nice thing with this scheme is that because the coordination is based on the spin loop CPU thread updating an atomic keepalive timestamp, cleanup is not required if a process crashes or exits weirdly. The keepalive will simply go stale and another thread will take ownership, using atomic instructions to guarantee that only one thread can become the new owner.






.jpg)