Captain's Log: Stardate 77875
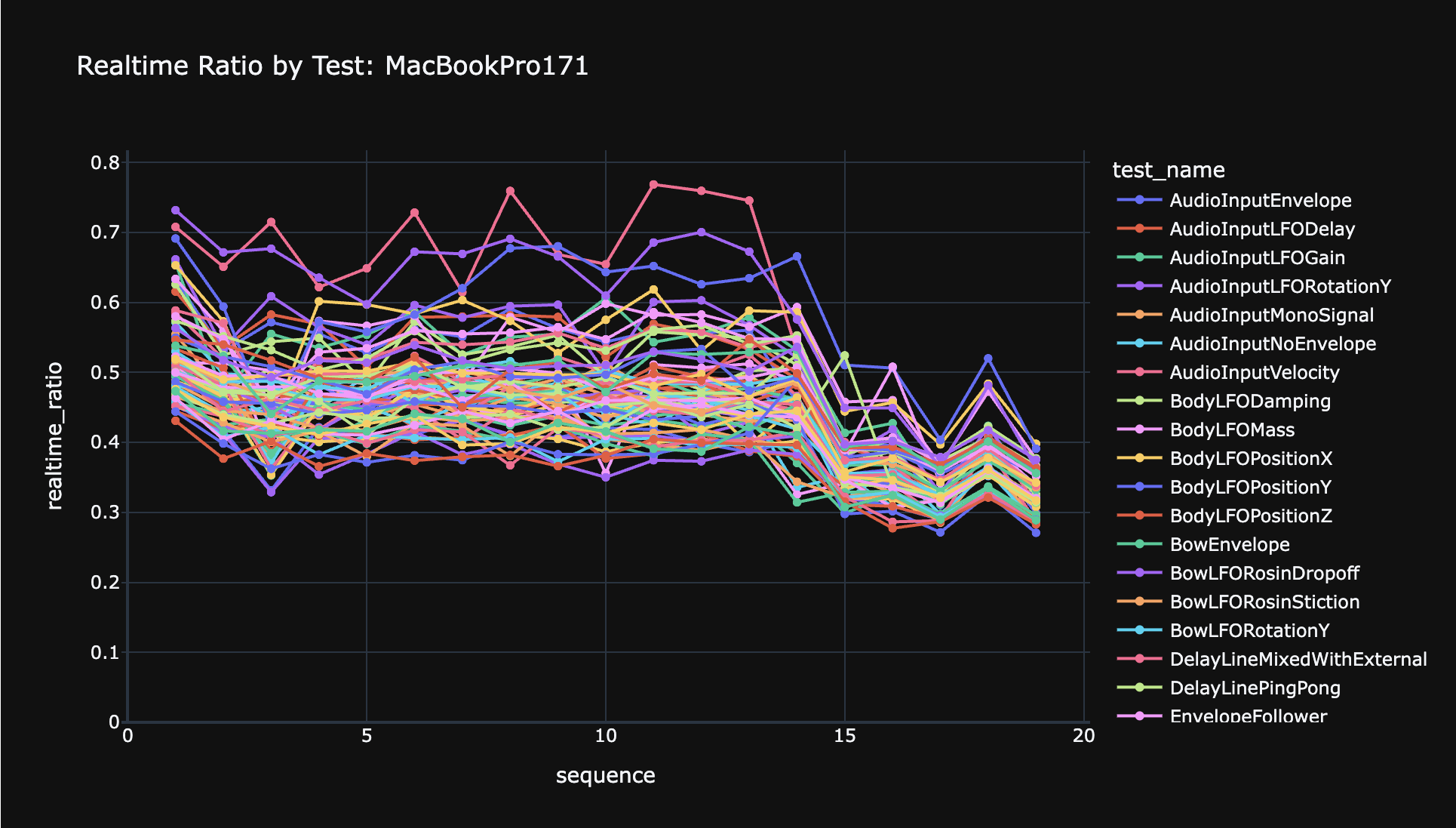
I now have two voice instances running on the GPU correctly, in parallel on different hardware work groups. Taking the output from either instance (with some PRNG fixup) passes all of the golden tests. This means that the CPU -> GPU memory layout stuff is all working, and the GPU code to handle multiple instances is done.
This is pretty exciting, because it means that this is all going to work. The remaining work is just a bunch of fiddly stuff on the CPU side to do voice allocation, and then to make sure the right MIDI data streams to each voice, etc. The main thing is that this test proves that the concept can work. I do think that I will have to do some significant optimizations to make sure everything on the CPU side is fast enough, since it now has to write out more data to the GPU (in voice-instanced mode). But I'm pretty sure that is not going to be a big deal.
One optimization I already implemented is that while the mutable entities have to all be duplicated in GPU memory N times for N voice instances, the Links (springs, etc) do not need to be duplicated. It took some doing to make sure that the Links don't contain any per-instance data, but it was possible, and this saves a ton of CPU time already, because links tend to outnumber all other entities combined.
Anyway this is all highly-encouraging. I'm pretty sure with a few day's more work, I can have basic voice instancing working. Of course that might be a couple weeks from now, given that I'm going to be doing PPG training for the next 10 days...






.jpg)