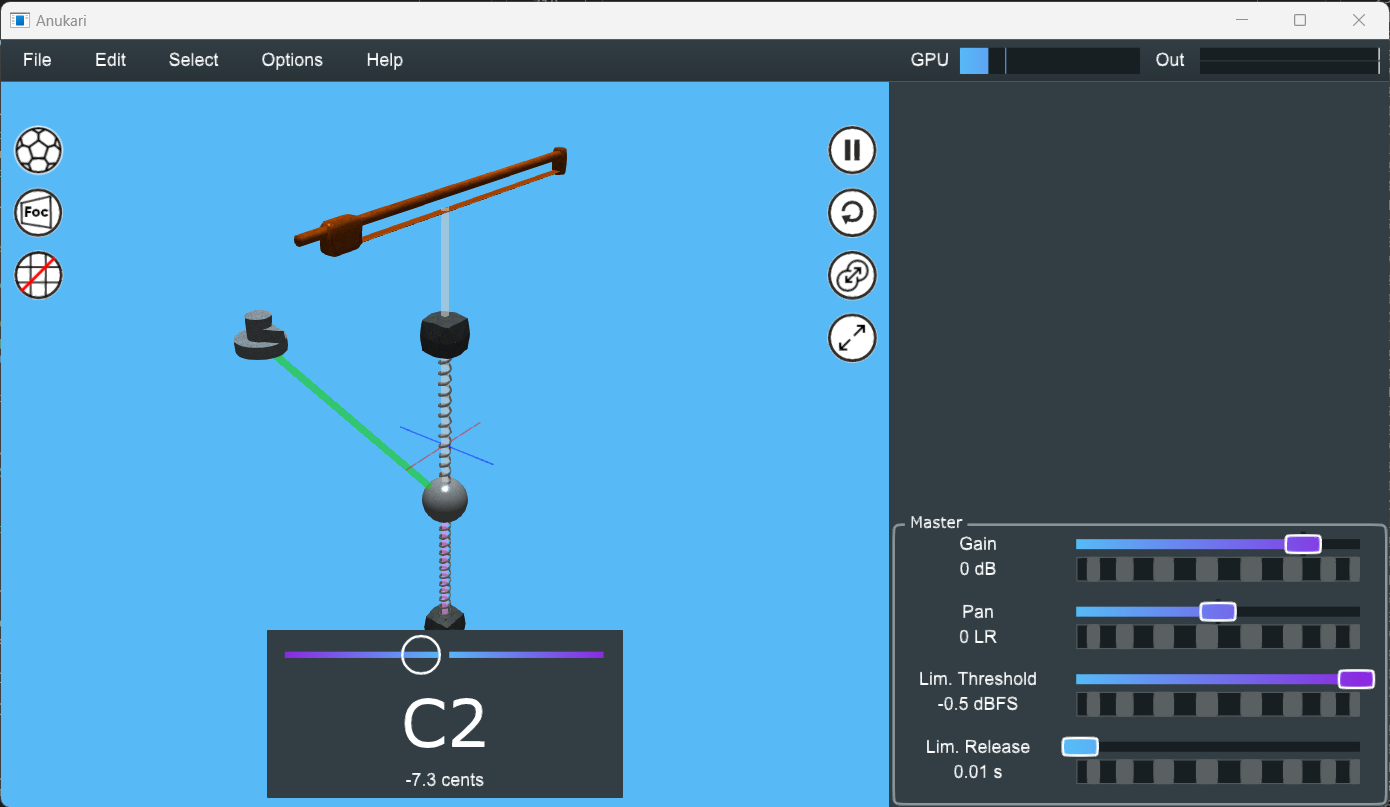
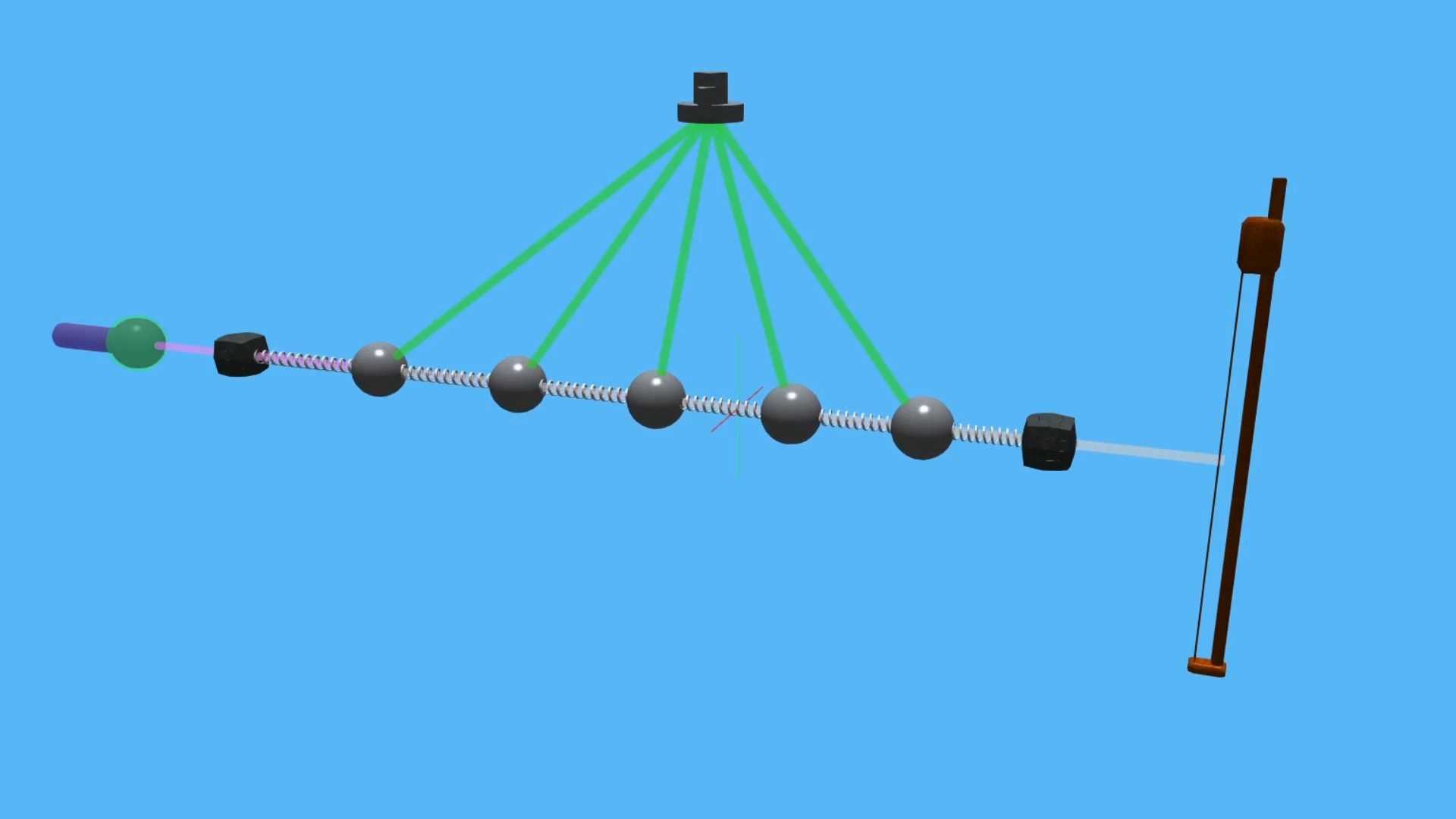
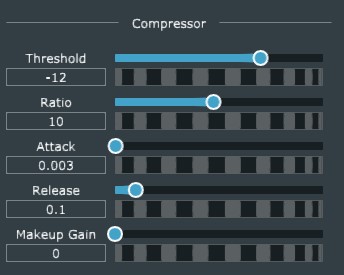
Captain's Log: Stardate 79603
Evan Mezeske
Feb 2026
Captain's Log: Stardate 79462.5
Dec 2025
Captain's Log: Stardate 79429.5
Captain's Log: Stardate 78674.7
Mar 2025
Captain's Log: Stardate 78089.3
Aug 2024
Captain's Log: Stardate 78086.6
Captain's Log: Stardate 78080.5
Captain's Log: Stardate 78069.7
Captain's Log: Stardate 78064.4
Captain's Log: Stardate 78061
Captain's Log: Stardate 78053.5
Captain's Log: Stardate 78026.5
Jul 2024
Captain's Log: Stardate 78017.3
Captain's Log: Stardate 78014.7
Captain's Log: Stardate 78006.4
Captain's Log: Stardate 78001.1
Captain's Log: Stardate 77998.1
Captain's Log: Stardate 77993.6
Captain's Log: Stardate 77988.1
Captain's Log: Stardate 77973.4
Captain's Log: Stardate 77907.5
Jun 2024
Captain's Log: Stardate 77850.6
May 2024
Captain's Log: Stardate 77820.5
Captain's Log: Stardate 77776.6
Apr 2024
Captain's Log: Stardate 77659.2
Mar 2024
Captain's Log: Stardate 77633.7
Captain's Log: Stardate 77609.5
Feb 2024
Captain's Log: Stardate 77593.4
Captain's Log: Stardate 77585
Captain's Log: Stardate 77569.1
Captain's Log: Stardate 77555
Captain's Log: Stardate 77439.9
Dec 2023
Captain's Log: Stardate 77168.9
Oct 2023
The Audio Units logo and the Audio Units symbol are trademarks of Apple Computer, Inc.
VST is a trademark of Steinberg Media Technologies GmbH, registered in Europe and other countries.