Captain's Log: Stardate 78129.1
I've been continuing to receive a ton of valuable feedback from the pre-alpha. The latest lesson I learned is that OpenCL features vary between MacOS versions. I cut a release the other day that worked great for me, and immediately broke for everyone using older MacOS versions (I'm on the latest). Thankfully the issue was clear from the logs of one of the users who had the problem.
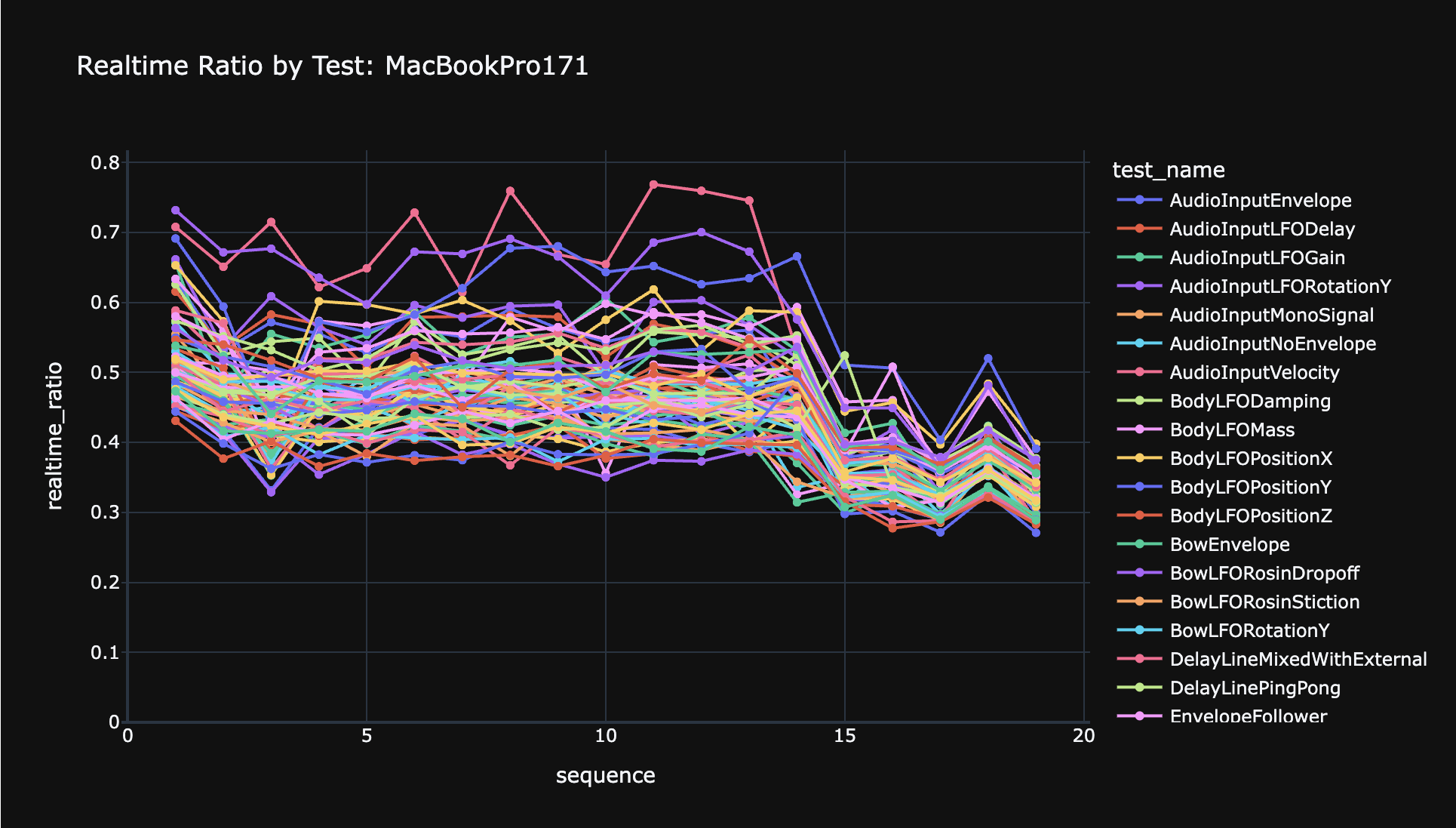
Anyway, the performance optimization I wrote about in the last post went out and has been very successful. My benchmarking shows that it reduced the time spent copying data between the CPU and GPU to a level that's insignificant compared to the time it takes to run the simulation kernel. This is great because it means there's no further optimization to do on the data-copying front. All the remaining work has to be in the kernel itself.
The state of affairs with the kernel is that on Windows, particularly with NVIDIA hardware, it runs great. You can run some very large presets (example) and the latency is pretty predictable. I want to improve things further here, and I believe the eventual CUDA port will help, but performance-wise it's pretty fun. (Stability still is an issue.)
However, on MacOS, things are in poorer shape. Despite cutting the memory latency out, the kernel is just a lot slower than on Windows. I've done some basic profiling using Instruments, and the best I can tell is that it is memory-bound, which offhand makes sense, but I think something fishy is happening. The best I could figure, the memory bottleneck was reading links (springs, etc). But in the preset I was benchmarking, the links only took up 11 KB of memory. Originally I imagined that this would fit in L1 cache, but while Apple's documentation is crap, I have found other sources that claim the M1 L1 cache is 8 KB. So that could really be a problem. Still, even smaller presets are slower than I'd expect, with links that would fit in 8 KB.
I also ran some experiments with ripping enough data out of some of the other structures in global memory so that I could reduce alignment from 256 bytes to 128 bytes, which you'd imagine might speed things up a lot. It didn't really do anything. This kind of confirmed that it wasn't these data structures that were problematic, but it left me wondering why not. Of course the performance is ultimately based on the holistic situation with memory reads, but it really seems like links are the biggest issue at the moment.
So I'm quite confused, and at the moment I am leaning towards starting the work to port the MacOS version to Metal instead of OpenCL, so that I will have total control over what's happening. It seems quite likely to me that Apple's OpenCL implementation is crap, given that they've deprecated it and really don't want folks using it -- why would they continue optimizing it? I don't see Metal as a silver bullet, but at least the profiling tools will work better, and there will no longer be any mysteries about what's happening.
One final note is that it appears that newer MacOS versions perform a lot better for OpenCL. Which is weird, and contradicts what I just wrote about Apple not maintaining it. I am curious if this means that the Metal implementation has improved, or what. I guess I'll find out.





.jpg)