Captain's Log: Stardate 79350.3
In part 1 of this series of posts, I explained the shortcomings in Anukari’s GPU implementation, and in part 2, I covered how the new CPU implementation manages to outperform the GPU version.
Prior to this change, I had invested a significant amount of time and effort on the GPU implementation (as the back catalogue of this devlog demonstrates). Obviously I would have preferred to find the improved CPU solution earlier, before putting so much effort into the GPU solution. In this 3rd and final installment I will reflect upon what went well, and what I could have done better.
The (unachieved) goal of 50,000 physics objects
As I discussed in part 1, my first prototype used the CPU. It was with this prototype that I “proved” to myself that to simulate the target number of physics objects that I wanted (50,000), the CPU was not an option.
I still think that this is true. Actually I’m even more confident, having now written a heavily-optimized CPU simulator. But where I went wrong was in my assumption about it being important to simulate 50,000 objects.
In my initial testing, I found that larger physics systems produced some really interesting results. I can’t quite recall how big of a system I had tested, but surely it was only a few hundred masses, maybe a thousand objects counting the springs.
From this I got excited and extrapolated out a bit too far. If 1,000 objects sound cool, 50,000 must sound even cooler, right?
Now, given that I’m currently writing about the avoidance of unfounded assumptions, I better not rule out the idea that 50,000 objects is really great. Maybe it is! But I never proved that. Furthermore, I did know that simulating 1,000 objects had excellent results.
Maybe I could have saved myself a lot of grief if I had questioned this assumption before building out all the GPU code.
On the other hand, I do want to give myself credit for being ambitious by going for the 50,000 goal. So I am not sure that I’ll criticize myself too much for going ahead with the GPU implementation. Overall I’d rather err on the side of being too ambitious than the opposite.
I think my real self-critique is not that I embarked on the GPU road, but that I stayed on it too long. When I first realized that I was not going to achieve my goal of 50,000 objects, that would have been a great time to take a step back and reevaluate whether the GPU was necessary.
At Google we often loosely used the rule of thumb that a 10x increase in system workload was about the time when you had to start thinking about redesigning a system (rather than incrementally optimizing it).
So changing my design goal by a factor of 50x should have been an obvious signal that maybe a different, simpler design was worth evaluating!
That said, at this point in the project I was not yet aware of how much of a headache using the GPU was going to be. So maybe I would have charged forth with the GPU anyway.
With these reflections out of the way, the reality of course is that I did eventually reevaluate my options and found a better solution. I do wish I had done this earlier, but I am proud of how quickly I changed horses once I began to realize that the one I was on was not optimal. I did not allow myself to succumb to the sunk cost fallacy, which is something I find personally challenging. So I’m happy about that.
And overall, of course, I’m pleased to have found a solution that works significantly better for my users, which is what’s really important to me.
On the drawbacks of using the CPU
The new CPU simulation is way faster and simpler than the GPU implementation, but that doesn’t mean there aren’t disadvantages.
One drawback to the change is that it might make me look foolish. I’m not too worried about this, though. I’d rather eat some crow and have a plugin that works really well than the alternative.
Another drawback is that the GPU support was potentially good from a marketing perspective. Using the GPU is unusual, and stands out as something interesting, like “alien technology.” Again, I am not going to lose any sleep over this. I didn’t write GPU code to make the plugin marketable. I used the GPU because at the time I thought it was the most effective way to make the plugin work really well.
The engineering drawbacks are more interesting. One advantage of the GPU is that it is mostly untapped processing power (for audio). So a user with a super CPU-hungry audio production setup might be able to run a GPU-based plugin, taking advantage of that extra processing capacity that would normally go unused.
This is in fact a great reason for plugin manufacturers to exploit the GPU. But of course this only makes sense if a plugin can be made to work really well on the GPU. I do not doubt that this is true for other plugins, but as I have written about at great length, for now Anukari runs much better on the CPU.
The way I see it, a plugin that works great but uses more CPU resources is always better than a plugin that works poorly and glitches but consumes less CPU. For me, Anukari’s usability trumps everything else. If users can’t reliably run interesting presets without glitching, nothing else matters.
That said, I do feel sad about anyone whom I’m disappointed with this change. It’s completely understandable that someone may have been excited by the GPU support (I sure was!), for any number of reasons. I do not enjoy letting anyone down.
But it’s not like I didn’t try to make the GPU support work! I invested many hundreds, if not thousands of hours into that approach. This devlog attests to that.
I also have to think about those users whom I’d disappoint if I didn’t improve Anukari’s performance. Many people’s machines could not run Anukari at all, and now they can. Many users who had glitching in Logic Pro before now find that the plugin runs flawlessly. VJs that run GPU-intensive visualization software can now run Anukari. The #1 complaint I’ve had since the start of the Beta is performance, and that is way less of an issue now.
Benefits of using the CPU aside from performance
Recall that for GPU support I was maintaining three backends: CUDA, Metal, and OpenCL. (Arguably I should also have supported AMD’s ROCm, but it’s a huge mess. That’s a whole other story.)
Now I’m just maintaining the one CPU backend. Granted, there is separate hand-written AVX and NEON code to support the two platforms, but this is limited to the hottest loops, and is not a big deal. AVX and NEON are far more similar to one another than the various GPU hardware and APIs are.
Overall the new simulator is vastly simpler than the old one. There’s much less indirection, since instead of orchestrating GPU kernels (including setting up buffers, managing data copies, etc) the code simply does the work directly.
This means that adding new features to the physics simulation is going to be substantially easier. This is exciting, because I have a gigantic spreadsheet of new features I’d like to add.
There’s also the fact that I just got all the future opportunity cost from dealing with GPU issues back. In other words, instead of spending hundreds more hours dealing with GPU compatibility issues, those hours will now go into new physics features, UX improvements, etc.
Also from a reliability perspective, the CPU code is far easier to test, profile, and debug. I can throw in log statements wherever I like. I can use the same instrumentation, profiler, and debugger as for the rest of the app. Unit tests are much simpler to write without having to call into the GPU code. And manual testing prior to releases no longer requires going through quite so big of a stack of laptops.
Keep in mind that I was previously spending time on horrific GPU issues like this AMD driver bug which was specific to just one AMD graphics chip. Now I have that time back.
I am really looking forward to making Anukari an even more interesting and useful sound design tool now that my time has been freed up to do so.
How tests helped make the GPU to CPU change possible
One thing that helped a lot in rewriting the physics simulation was the existing body of tests. Since the prior GPU implementation supported multiple backends, all the tests were already backend-agnostic. These tests are extremely thorough, so while writing the CPU backend, I was basically doing test-driven development.
I can’t imagine how much harder this would have been without the tests. They caught way more issues than I can count. And once I had them all passing, it gave me enormous confidence that the new simulation was working correctly.
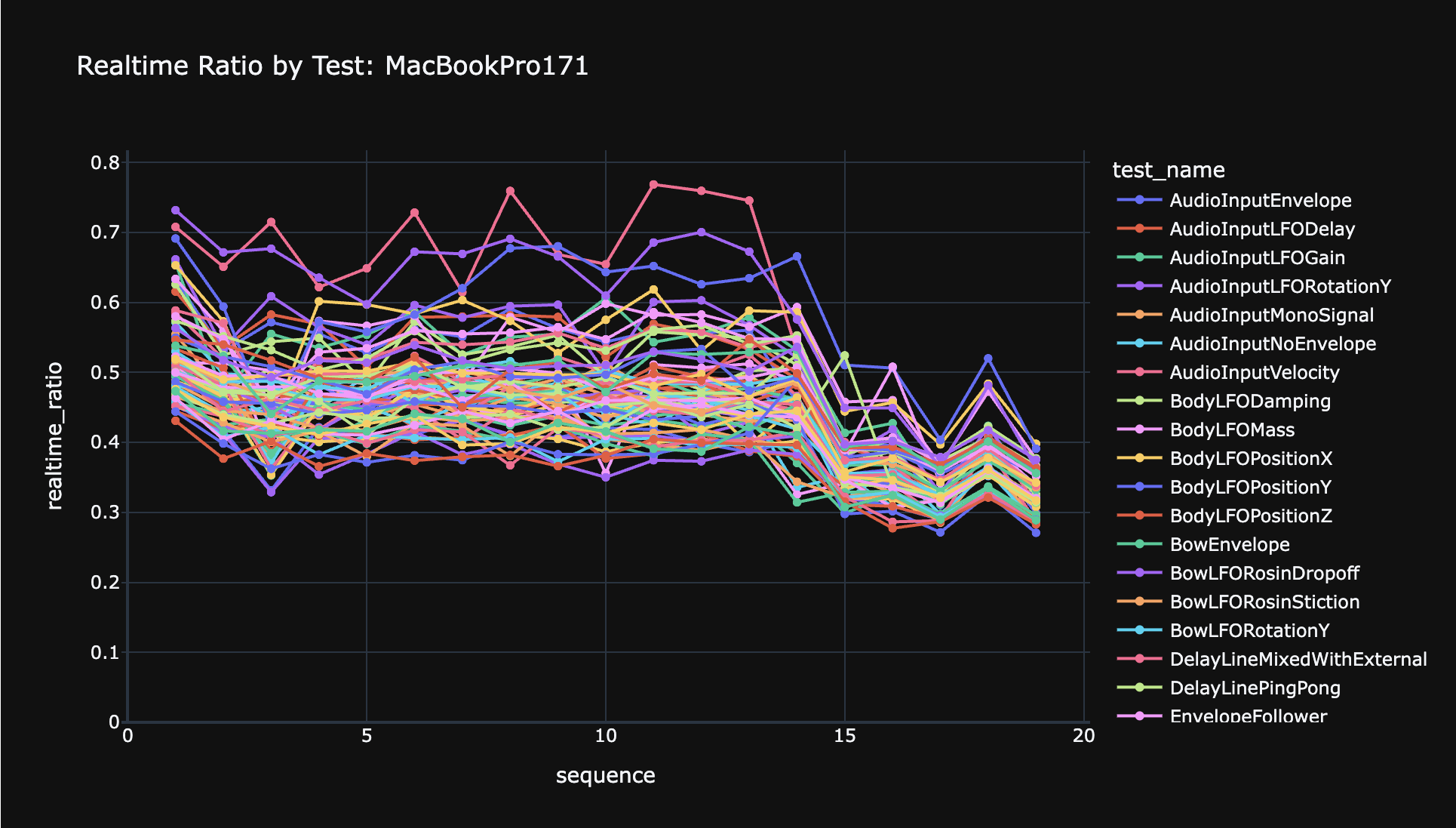
Far and away the most useful tests were my golden tests. At the moment I have close to 150 tests that each load an Anukari preset, feed in some MIDI/audio data, and generate a short audio clip. This clip is fingerprinted and compared to a “golden” clip. Most of the golden tests isolate individual physics features to prove that they work, but there are a few tests that run large, complex presets to prove that interactions across features work as well.
Once the golden tests were passing, I was completely sure that I had implemented all the physics features correctly.
Correct audio output is obviously important, but stability is just as important. The CPU code is heavily-optimized and does a lot of low-level memory access stuff where it’s easy to screw up and crash by accessing the wrong memory.
For this, I mostly relied on fuzz testing and the chaos monkey.
For the fuzz tests, I have a testing API that can generate random mutations to an Anukari preset. The API is, in principle, capable of generating any Anukari preset. When I’m adding a new physics parameter, one of the very first things on my checklist is to update the fuzz API to be aware of it.
I use this API in a number of fuzz tests. The basic pattern is a loop that makes a random preset mutation, and then checks an invariant. Doing this tens of thousands of times tends to catch all kinds of bugs, especially because the random presets it generates are just awful, twisted messes. When randomly setting parameter values, the fuzz API has a slight preference for picking values at the extremes of what Anukari supports, so it ends up generating super weird presets that a human would never create.
One of the fuzz tests generates presets in this way and then simulates them, verifying that the simulation’s output is reasonable (i.e. no NaN/inf, etc). And of course these tests verify that no inputs can cause the simulator to crash. Running the fuzz test loop for a long enough time with no crashes gave me huge confidence that I had worked out all of the crash bugs in the new simulator.
The chaos monkey is sort of the last line of defense. It opens the standalone Anukari app and generates random mouse and keyboard inputs. This has mostly been useful for catching GUI bugs and crashes, but it also verifies that the simulator does not crash in real-world conditions.
It’s hard to say, but I think that without all these tests, my CPU rewrite attempt may have simply failed. At the very least it would have taken 5x as long. The golden tests were especially important. I can’t imagine manually setting up presets and checking that 100+ individual physics features worked correctly, over and over.
The value of generative AI
I wrote above about how I wish I would have tried a SIMD-optimized CPU solution for Anukari’s physics simulation earlier in the project.
One subtle issue with that idea, though, is that 2 years ago I wasn’t really using GenAI for programming. I had played with it a bit, of course, but it wasn’t a core part of my workflow.
I’m not sure how successful my SIMD attempts would have been without GenAI. I’m no stranger to assembly code, but I am far from fluent. We might say that I speak a little “broken assembly.” The main issue is that I write assembly very slowly, as I have to frequently reference the documentation, and I’m not always aware of all the instructions that are available.
So if I had attempted the SIMD approach a couple years ago, it would have gone way more slowly. I could not have experimented with multiple approaches without a lot more time.
Starting about a year ago, GenAI became a core part of my programming workflow. I don’t find that “vibe coding” works for me, but GenAI is an amazing research assistant.
By far the highest leverage I’ve found with GenAI is when I am learning a new API or technology. Having the LLM spit out some example code for the problem I’m solving is incredibly valuable. I always end up rewriting the code the way I want it, but it saves a ridiculous amount of time in terms of figuring out what API functions I need to call, what headers those come from, the data types involved, etc.
For writing the SIMD code, GenAI was a massive superpower. Instead of constantly fumbling around in the documentation to figure out what instructions to use, I asked GenAI and it immediately pointed me in the right direction.
I mostly wrote AVX code first, and then ported it to NEON. This is probably the closest that I approached to vibe coding. In many instances, asking GenAI to translate AVX to NEON, it produced perfect working code on the first try, at least for simple snippets.
Don’t get me wrong, GenAI also produced a ton of absolute garbage code that wasn’t even close to working. But that’s not really a problem for me, since I don’t use it for vibe coding. I just laugh at the silly answer, pick out the parts that are useful to me, and keep going.
Not only did GenAI save me a lot of time in scouring documentation to find what I needed, but also I ended up running experiments I otherwise would not have. This is one of those situations where a quantitative effect (writing code faster) turns into a qualitative effect (feeling empowered to run more interesting experiments).
The “superpower” aspect was really the fact that GenAI emboldened me. Instead of worrying about whether it was worth the time to try an optimization idea, I just went ahead with it, knowing that my research assistant would have my back.
Appendix: Further challenges with using the GPU for audio
One last detail to mention is that running Anukari’s simulation on the GPU also incurs overhead from scheduling GPU kernels, waiting for their results, etc. While it’s nice to avoid this overhead, it’s actually extremely tiny on modern machines. Especially with Apple’s Metal 4 API and unified memory, this overhead is not very consequential, except at the very smallest audio buffer sizes.
However even if the fast-path overhead of GPU scheduling is good, there are still problems. Notably, GPU scheduling is not preemptive. Once a workload is scheduled, it will run to completion. This means that if another process (say, VJ visualization software) is running a heavy GPU workload, it can interfere with Anukari’s kernel scheduling, leading to audio glitches. To some extent this can be ameliorated using persistent kernels, but all kernels have deadlines and thus need to be rescheduled periodically, opening the door to glitches.
The fact that GPU tasks are not preemptive is a fundamental issue in the world of realtime audio. It’s not unsolvable (e.g. permanent task persistence could be a solution), but it is tricky. It’s also worth noting that the macOS Core Audio approach of using workgroups for audio threads does not apply to the GPU, so the OS has no way of knowing that a GPU task is realtime. This is an OS-level feature that Apple could add to make GPUs more audio-friendly. But given how little the GPU is used for audio, it seems very unlikely that Apple will invest in this.
I don’t think that true preemption on the GPU is something that would ever be realistic. Between the huge amount of register memory and threadgroup memory that GPUs have, switching a threadgroup execution unit between workloads would be way too expensive. We’re talking about copying half a megabyte of state to main memory for a context switch.
This means that even if GPU APIs supported kernel priority (which they mostly don’t), it still could not solve the audio glitch issue, because if the GPU was already fully utilized with running tasks, even a realtime-priority task could not preempt them. The priority would only mean that the task would be the first to start once the existing workload was finished.
Probably the only true solution for flawless audio on the GPU would be for the OS to provide support for reserved GPU cores, alongside realtime priority for low-latency signaling between the CPU and GPU. This would allow realtime applications to run persistent kernels on the reserved cores without any issues with other workloads “sneaking in.”
I believe that Apple might be able to figure out a solution to this and pull it off. NVIDIA also. Definitely not AMD, though, their drivers are hopeless to begin with, even for the simplest use cases. Also I would not expect Intel’s integrated graphics to do this. So even in a perfect world where GPU vendors decide to make audio support a first-class priority, in my opinion its usefulness will be limited to the two top vendors, and users with Radeon or Intel graphics will not benefit.
(Maybe at some point I will write more about these challenges, and the solutions I came up with, but for now I am mostly happy to just move to the CPU and forget all these complex headaches.)





.jpg)